
Un “contenitore” è una modalità di virtualizzazione (termine in realtà non propriamente corretto) a livello di sistema operativo che permette di lanciare multipli sistemi GNU/Linux, tra di loro isolati, su un unico sistema host. In questa definizione rientra LinuX Container ( LXC ), una soluzione leggera ed efficiente per ottenere facilmente i risultati della definizione precedente. Un simile scenario lo abbiamo già incontrato in chroot o in systemd-nspawn ; e in effetti è proprio rispetto a quest’ultimo che ci sono diverse affinità, in particolare nell’utilizzo di alcune funzioni implementate, e in continuo sviluppo, nella mainline del kernel Linux. Poiché i container sono in continua crescita e molto popolari come sistema basilare di virtualizzazione nel market odierno, abbiamo deciso di fornire una descrizione puntuale anche di LXC, con alcuni esempi applicativi.
Principio di funzionamento
I contenitori Linux sono una soluzione leggera e parzialmente alternativa alla virtualizzazione completa ottenuta con hypervisor come KVM , VirtualBox
o VMWare , sebbene a rigore tale comparazione risulti forzata poiché sarebbe più corretta nei confronti di progetti come OpenVZ , Docker o BSD Jails.
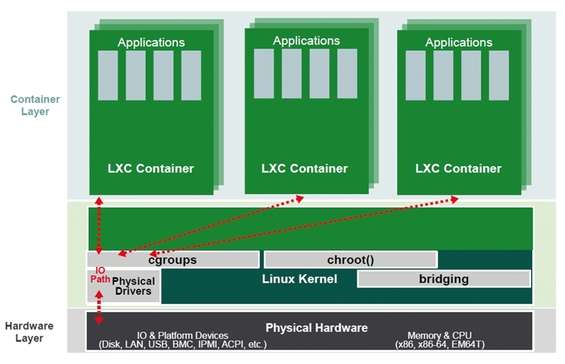
Interazioni di LXC con alcune funzioni del kernel
A partire dal 2007 il kernel Linux comprende alcune funzioni capaci di limitare e isolare l’uso delle risorse hardware come CPU, memoria, I/O disco e porte di comunicazione. Queste funzioni vengono identificate dal nome CGroups ( Control Groups ) attraverso le quali l’amministratore può esercitare un controllo minuzioso sulla gestione delle risorse ad opera dei processi che le utilizzano. Un CGroups associa un insieme di task, scelti dall’amministratore, con un insieme di parametri per uno o più sottosistemi ( subsystem ). Un subsystem è un modulo che fa uso del raggruppamento dei task, fornito da CGroups, al fine di trattare il gruppo di task (processi) in un determinato modo. Un subsystem, allora, è il controllore della risorsa che applica alla lettera i limiti imposti dall’amministratore attraverso gli appositi gruppi, alcuni elencati di seguito:
blkio : imposta dei limiti in materia di accesso ai dispositivi a blocchi che in GNU/Linux sono hard disk (stato solido o “classici”), device USB etc;
cpu : attraverso lo scheduler del kernel permette di fornire limiti in materia di accesso alla CPU;
cpuacct : genera automaticamente dei report sull’uso della CPU ad opera dei processi per quel dato CGroups;
cpuset : nei sistemi multi-core assegna individualmente ogni core al gruppo di processi;
devices : monitora e fa rispettare le restrizioni imposte sui device file;
freezer : permette di sospendere e/o far riprendere le attività nell’insieme di processi appartenenti a quel dato gruppo di controllo;
memory : impone restrizioni sull’uso della memoria e genera automaticamente dei report sulla risorsa RAM utilizzata dai vari processi di quel dato gruppo.
Per l’elenco completo e la descrizione puntuale con annessa sintassi si rimanda alla documentazione del kernel nel percorso /usr/src/
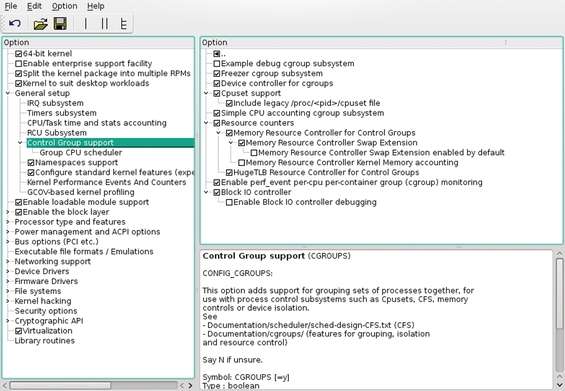
Alla voce General Setup abbiamo Control Group e Namespaces support
Questa funzione fornisce un modo affinché task differenti possano utilizzare il medesimo ID in uno spazio nomi differente senza creare conflitti tra ID uguali. In questo modo, si fornisce al gruppo di processi l’illusione che sono gli unici presenti sul sistema.
È evidente allora come uno degli usi più frequenti dei Namespaces è sostenere la creazione dei container. Attualmente il kernel Linux implementa sei voci per il Namespaces:
Mount : isola l’insieme dei mount point nel file system visto da un gruppo di processi. In questo modo i processi nei diversi namespaces possono avere “visioni” differenti della gerarchia del file system;
UTS : nel contesto di un container, l’UTS namespace permette ad ogni contenitore di avere un proprio hostname e NIS (Network Information Service) domain;
IPC : ogni IPC (Inter-Process Communication) namespace ha una propria serie di identificatori. Questo permette di isolare la comunicazione tra processi, ad esempio una coda di messaggi;
PID : isola l’ID (IDentifier) del processo. In sostanza processi differenti in un differente spazio dei nomi può avere il medesimo ID senza che questo crea conflitti;
Network : fornisce il totale isolamento delle risorse associate alla rete. Ovvero ogni rete in uno spazio nomi ha il proprio indirizzo IP, tabella di routing, numero porta, ecc.;
User : permette di isolare UID e GID. In sostanza l’UID e il GID utente può differire tra interno e esterno di un diverso namespace.
Virtualizzazione completa e contenitori hanno vantaggi e svantaggi. Mentre la prima offre un totale isolamento del sistema guest dal sistema host (e viceversa), ma al costo di un importante sovraccarico poiché ogni sistema virtualizzato lancia un proprio ambiente completo di kernel emulando anche l’hardware sottostante, i contenitori offrono un minor grado di isolamento (e di riflesso anche di sicurezza), ma al tempo stesso anche un minor overhead dovuto alla condivisione del kernel e delle risorse con il sistema host.

Soluzione intermedia dei container Linux: un ambiente chroot “dopato”
Allora non esiste una metodologia meglio dell’altra, ma piuttosto tra loro complementari: ognuna offre vantaggi e svantaggi da valutarsi a seconda della specifica situazione applicativa.
La tecnica di “virtualizzazione leggera” attraverso LXC offre un ampia gamma di possibili applicazioni tra le quali la possibilità di avere diverse macchine Linux su un solo server hardware, servizi come Web server o database server lanciati in un ambiente isolato, sandbox ovvero applicazioni all’interno di contenitori un tipico approccio per sviluppare/testare software in un ambiente isolato, lanciare un differente rilascio di una distribuzione GNU/Linux nonché avere differenti distribuzioni sullo stesso sistema host.
Il principale svantaggio di LXC (e dei container in generale) è che, utilizzando il kernel Linux del sistema host, non è possibile lanciare un sistema operativo differente. Dal punto di vista della sicurezza avere utenti non privilegiati in un container Linux non differisce dall’avere utenti non privilegiati sul sistema host. Il problema potrebbe sorgere quando, in determinate condizioni, si permette l’accesso come utenti privilegiati a un contenitore LXC. Per questo motivo a partire dalla versione 3.14 del kernel e dalla versione 1.0.5 di LXC, è possibile configurare e gestire container non privilegiati. Ciò lo si può ottenere mappando il container con UID diverso da 0 (laddove 0 indica l’utente root, privilegiato).
Verifiche iniziali
Prima di approcciare LXC partendo con semplici applicazioni, il primo passo da compiere è verificare che la distribuzione risulti pronta all’uso dei container. LXC è caratterizzato da due componenti: una in userspace contenente gli strumenti necessari al controllo e alla gestione del container e una insita nel kernel e con esso sviluppata, CGroups e Namespaces. Allora tre sono le verifiche da effettuarsi: come prima assicuriamoci che sia installato il pacchetto lxc e qualora non lo fosse procediamo alla sua installazione, pacchetto indispensabile per l’amministrazione in userspace. Terminata l’installazione verifichiamo se il kernel ha le specifiche componenti già abilitate: in genere lo sono di default in molte distribuzioni. Apriamo un terminale e impartiamo il comando lxc-chkconfig assicurandoci che le voci relative alle sezioni Namespaces e Control groups siano tutte abilitate, nel qual caso occorre ricompilare il kernel.

Voci abilitate e filesystem montato di default: possiamo iniziare
Ultima verifica è assicurarsi che il file system cgroup del kernel sia montato utilizzando il comando mount grep cgroup il cui output, alla luce di quanto riportato in precedenza, dovrebbe apparire meno criptico.
Se il file system cgroup non è montato, dobbiamo operare manualmente al fine di crearne la gerarchia e collegare i vari subsystem. Da utente amministratore si crea dapprima un mount point includendo il gruppo, ad esempio mkdir /cgroup/cpu , quindi si procede al montaggio con il comando mount -t cgroup -o cpu /cgroup/cpu .
Approccio iniziale
Terminate le verifiche possiamo lanciare il nostro primo contenitore. Apriamo un terminale e, attraverso sudo o effettuando l’autenticazione come utenti amministratori, scriviamo il comando lxc-execute -n contenitore1 /bin/bash e premiamo Invio . All’apparenza nulla sembra essere accaduto, ma un’analisi più attenta mostrerà che il “nuovo” prompt appartiene alla shell Bash lanciata all’interno del container di nome contenitore1 . Per accertarcene è sufficiente impartire il comando pstree ( man pstree ) per ottenere un eloquente init.lxc—bash—pstree o anche ps axf ( man ps ) per vedere i 3 processi ad albero. Cosa è avvenuto? Il comando lxc-execute ( man lxc-execute ) è utilizzato quando si vuole lanciare un’applicazione in un ambiente isolato, la shell Bash nel nostro caso. Attraverso l’uso del processo init.lxc (con PID=1 all’interno del contenitore) viene eseguita la shell Bash (PID=2) e i successivi comandi impartiti nella shell del contenitore avranno PID superiori. Per uscire da questo semplice contenitore è sufficiente impartire il comando exit e ritorneremo al terminale “originario”.
Come rendere permanenti le impostazioni
Quando con la configurazione si interviene sulle interfacce di rete, così come riportato nell’articolo, le modifiche sono provvisorie, ovvero spegnendo il computer queste si perdono. Allora se vogliamo operare in maniera permanente occorre mettere mano ai file di configurazione e del (o dei) container così come dell’host. Questi file differiscono a seconda della distribuzione. Per Debian e derivate occorre intervenire sul file /etc/network/interfaces . File diverso per Red Hat e derivate (ad esempio Fedora e CentOS) per le quali un nuovo file, ad esempio di nome ifcfg-br0 , dovrà essere scritto e salvato nella directory /etc/sysconfig/network-scripts . Anche una OpenSUSE vede la scrittura di un file, ad esempio di nome ifcfg-br0 , ma da salvare in /etc/sysconfig/network . Per le sintassi, che esulano da questo articolo, si rimanda alla documentazione delle distribuzioni.
Un primo approfondimento
Visto così appare tutto molto semplice, in realtà con i container Linux si possono realizzare topologie di rete estremamente complesse, tali da mettere in difficoltà anche le persone più esperte. Un container isolato dal resto del mondo può tornare utile per testare codice sperimentale altamente instabile, ma se quel codice è un’applicazione Web che fornisce un servizio, sia esso un web server, un database o altro, mantenerlo isolato non ha alcun senso. Allora un importante aspetto dei container, oltre a limitare opportunamente le risorse che può sfruttare sul sistema host, sta nella scelta del collegamento con il “mondo esterno”. Come fa LXC a sapere quale implementazione di rete e/o limitazioni cgroups utilizzare? Attraverso un’opportuna configurazione suddivisa in due parti: la configurazione del container che vogliamo creare e la configurazione generale di LXC. Il file default.conf in /etc/lxc/ , o in ~/.config/lxc/ per container di utenti non privilegiati ( man 5 lxc.container.conf ) per un comportamento di default e, nei medesimi percorsi, è possibile creare il file lxc.conf da utilizzarsi per l’impostazione dei limiti, la configurazione dei percorsi, la rete e molto altro ancora ( man 5 lxc.system.conf ). I file di configurazioni in /etc/lxc/ possono avere anche nomi diversi, infatti sarà possibile richiamare lo specifico file da associare a quel dato container utilizzando un’opzione all’atto della creazione come vedremo tra breve. Ora, vi sono due modi per connettere LXC con il “resto del mondo” e il sistema host in primis, uno dei più utilizzati è attraverso un’operazione di bridging. Vediamo come procedere. Questa operazione non è necessaria agli utenti Ubuntu poiché automaticamente viene configurato un bridge di nome lxcbr0 nonché un dnsmasq nel momento in cui si installa LXC ( sudo apt-get install lxc ). Un bridge è un dispositivo di rete, precursore dello switch, con il quale è possibile collegare due segmenti di rete, ciascuno dei quali può essere costituito potenzialmente da molti dispositivi host. Per procedere assicuriamoci di aver installato il pacchetto bridge-utils quindi apriamo un terminale, assumiamo le credenziali dell’amministratore e aggiungiamo un bridge virtuale identificato dall’interfaccia br0 con brctl addbr br0 (per approfondimenti man brctl ). L’utility brctl è definita deprecata al momento di scrivere: se non la si vuole utilizzare è possibile creare un bridge virtuale anche con il comando ip link add br0 type bridge (per approfondimenti man 8 ip ). Dopo questa operazione i comandi brctl show br0 , o ip link show , mostreranno la creazione dell’interfaccia br0 che dovremo far utilizzare dal container. Ma come? Creando un file di configurazione con le seguenti righe:
lxc.utsname=container1
lxc.network.type=veth
lxc.network.link=br0
lxc.network.flags=up
lxc.network.ipv4=192.168.1.100/24
lxc.network.name=eth0
Analizziamo le singole opzioni. La prima riga specifica l’hostname per il contenitore. La seconda riga il tipo di rete che dovrà essere utilizzata per il container tra le varie modalità supportate: none , empty , veth , vlan , macvlan , phys . Per motivi di spazio non possiamo analizzarle tutte e nemmeno nel più piccolo dettaglio. Nel seguito utilizzeremo la modalità veth la quale specifica un dispositivo di rete condiviso che da un lato è assegnato al container e all’altro estremo collegato (virtualmente) al bridge riportato alla riga successiva (opzione lxc.network.link ) che specifica su quale interfaccia dovrà passare il traffico di rete, br0 nel nostro caso. L’opzione lxc.network.flags se impostata su up attiva l’interfaccia all’atto dello start del container. L’indirizzo IPv4 in formato CIDR da assegnare all’interfaccia virtualizzata del container è specificato con l’opzione lxc.network.ipv4 mentre l’ultima riga rinomina l’interfaccia del container, un’opzione non indispensabile, ma in alcuni casi potrebbe ritornare utile poiché l’allocazione ad opera di LXC è dinamica. In questo modo la “blocchiamo” sull’interfaccia (del container) eth0.
Copiamo le righe in un file container1.conf che salveremo in /etc/lxc/ . Assegniamo al bridge br0 un indirizzo statico e attiviamolo:
ifconfig br0 192.168.1.10 netmask 255.255.255.0 up
Dopo aver premuto Invio diamo il comando ifconfig senza parametri per vedere la nuova interfaccia. A questo punto, eseguiamo di nuovo la shell Bash nell’ambiente del container ma questa volta gli facciamo leggere il file di configurazione con l’opzione -f :
lxc-execute -n container1 -f /etc/lxc/container1.conf /bin/bash
Premendo Invio verrà lanciata di nuovo una shell bash isolata in un container: da questa shell Bash il comando hostname ( man hostname ) mostrerà il nome del contenitore. In più un ping all’indirizzo 192.1681.1.10 del bridge mostrerà la raggiungibilità dello stesso, viceversa un ping in una shell del computer host all’interfaccia virtualizzata “interna”, ping 192.168.1.100, ne mostra la sua raggiungibilità. Cosa abbiamo creato? Poiché una immagine vale più di 100 parole è sufficiente osservare la figura seguente.
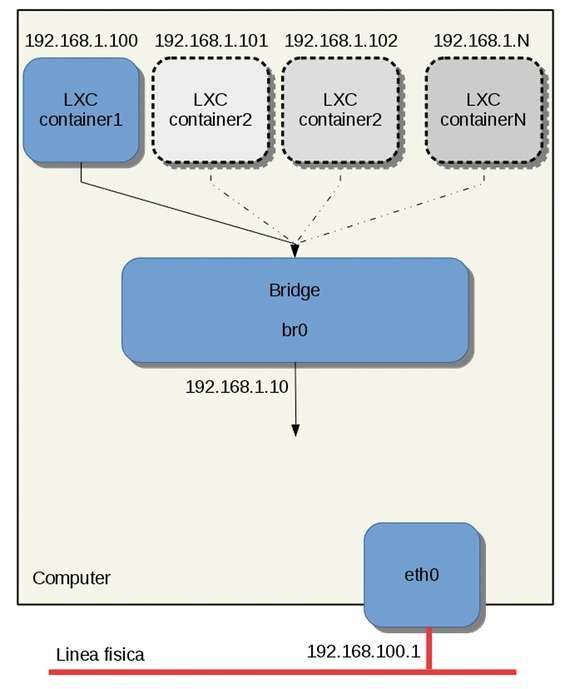
Il container1 collegato al bridge virtuale e visibile dall’host
Se presente sull’host, possiamo aggiungere un’interfaccia di rete, ad esempio eth0, al bridge con brctl addif br0 eth0 e verificarne l’aggiunta con brctl show . A questo punto possiamo impostare l’IP per br0 così come lo era (o lo si può fare) per eth0 su un normale host. In questo modo eth0 diventa “non configurata” e br0 prende il posto di eth0 nell’host permettendo così di raggiungere gli altri nodi della LAN e, in funzione della topologia della rete, anche Internet. Il file container1.conf riportato è il più semplice che possiamo creare e in quanto tale anche il più incompleto. Il pacchetto LXC mette a disposizione un certo numero di esempi che possiamo trovare in /usr/share/doc/packages/lxc/examples/ : aprendo ogni singolo file e aiutandosi con il manuale ( man lxc.continaer.conf ) possiamo agevolmente capire e approfondire le varie voci.
Notazione CIDR: qualche chiarimento
Il Classless Inter-Domain Routing indica un indirizzamento senza classi dove il limite fra i bit destinati a indicare l’indirizzo di rete e quelli destinati a indicare l’host finale può essere posto in qualunque punto dei 32 bit (indirizzi IPv4). In questo modo si possono accorpare più classi su un’unica rete o suddividere una data classe. Detta così può sembrare una cosa complicata, ma un esempio dissiperà i dubbi. L’indirizzo 192.168.111.11/24 altro non sta ad indicare che un indirizzo di rete pari a 192.168.111.11 appartenente al segmento di rete 192.168.111.0 , il cui indirizzo di broadcast è 192.168.111.255 , presenta una netmask pari a 255.255.255.0 e l’indirizzo degli host può variare nel range 192.168.111.1 fino a 192.168.111.254 per un totale di 254. Altro esempio, 192.168.111.11/23 indica una netmask 255.255.254.0, rete 192.168.110.0, broadcast 192.168.111.255 per un totale di 510 host, con range indirizzi da 192.168.110.1 fino a 192.168.111.254. In questo caso specifico avremo due sotto-reti (192.168.110.0 e 192.168.111.0) in grado di comunicare senza necessità di instradare pacchetti tramite un router. In rete esistono dei “calcolatori” che permettono di valutare automaticamente questi indirizzi in notazione CIDR; un esempio lo troviamo qui .
Contenitori pronti all’uso
Altra peculiarità di LXC è quella di metterci a disposizione dei template (modelli) di svariate distribuzioni (che oltremodo possiamo personalizzare) pronti per essere utilizzati come container da replicare più e più volte ottenendo quanto visibile nelle figura precedente per i contenitori tratteggiati e, una volta configurata la rete per ognuno di essi, tutti raggiungibili attraverso i loro indirizzi dal computer host. Troviamo questi modelli in /usr/share/lxc/templates/ . Provando ad aprirne uno con un editor di testo noteremo come risultino dei normali script shell che automatizzano tutta la procedura dal download dei pacchetti alla creazione dell’ambiente (contenitore) in /var/lib/lxc/nome_contenitore . Come li utilizziamo? Se proviamo ad impartire il comando apropos lxc ricercheremo nei nomi e nelle descrizioni delle pagine di manuale la parola lxc: ci verrà restituita una lista di elementi legati anche a LXC. Scorrendo i nomi troviamo lxc-create ( man 1 lxc-create ) che ci permette di creare dei contenitori. Ad esempio, supponiamo di voler creare nella distribuzione in uso, una OpenSUSE, un contenitore con il template associato a Debian, la sintassi vede:
lxc-create -n debian-veth1 -t /usr/share/lxc/templates/lxc-debian
laddove l’opzione -n indica il nome da dare al contenitore (in genere un nome evocativo) e l’opzione -t il nome, con il percorso, al file del template. Dopo aver premuto Invio il primo rigo che apparirà sarà:
Checking cache download in /var/cache/lxc/debian/rootfs-jessie-amd64
questa verifica viene fatta al fine di valutare la presenza di altri container simili.
Infatti, se volessimo creare un container uguale per poi modificarne il file di configurazione, o comunque dedicarlo a un servizio diverso dal precedente container, la procedura non scaricherà di nuovo tutto da zero, ma prenderà come riferimento quanto già creato. Infatti, se provassimo a impartire il comando lxc-create -n debian-veth1 -t /usr/share/lxc/templates/lxc-debian con nome differente, ad esempio debian-veth2 , verrà creato un secondo container uguale al primo, ma con il nuovo nome indicato e in un tempo estremamente ridotto poiché andrà a copiare la rootfs già creata per il precedente container. Il numero di container creati, i rispettivi nomi, nonché i relativi indirizzi ad esso associati (qualora lo fossero e/o fosse stato configurato un DHCP) li possiamo elencare con il comando lxc-ls -fancy . Quando vogliamo avviare un container è possibile utilizzare lxc-start -n nome_container . Nella figura seguente vediamo, nella shell in alto, l’avvio dei contenitori di nome container1 e debian-veth1 : il primo può scambiare dati con l’host mentre il secondo è isolato (così come gli altri due in stato di stop). Dalla shell centrale osserviamo come il contenitore isolato lanci una shell Bash (shell di login) all’atto dell’autenticazione e venga attivato il servizio ssh. Questo vuol dire che, una volta configurato un indirizzo per tale container, vi è possibile accedere, una volta avviato, previa autenticazione da remoto sfruttando il servizio SSH.
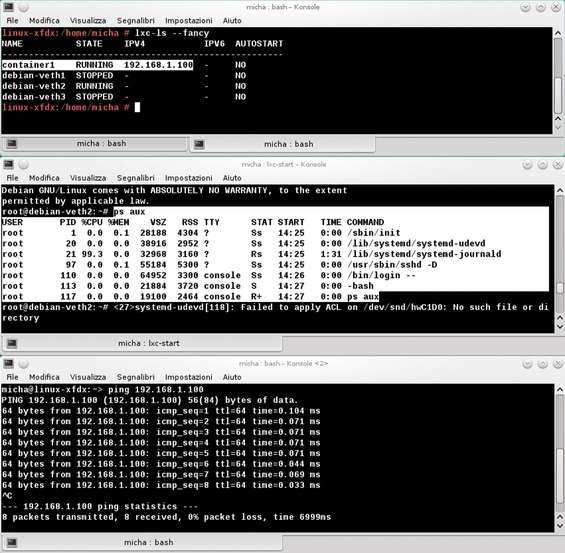
Una pila di contenitori
Nell’ultima shell vediamo come un ping sull’interfaccia di container1 ne verifichi la raggiungibilità. Una nota sull’output della prima shell. Osserviamo la dicitura AUTOSTART che su tutti i container è impostata su NO . La funzione autostart torna utile per poter avviare automaticamente uno o più container all’atto dell’avvio della distribuzione, della macchina virtuale o più in generale di un server. Per avere attiva questa funzione è sufficiente inserire nel file di configurazione l’opzione lxc.start.auto=1 in genere accompagnata all’opzione lxc.start.delay=numero_secondi che dice al container di aspettare N secondi al termine dell’avvio del computer prima di lanciare automaticamente il container come da opzione precedente. Osserviamo come i file di configurazione dei container creati in /var/lib/lxc non sono in /etc/lxc/ , ma vengono creati come file config , e in quanto tali leggibili da un editor di testi, in /var/lib/lxc/nome_container/ dalla procedura automatica contenuta nello script del template. Per fermare un container viene utilizzato il comando lxc-stop -n nome_container . Quanto fin qui riportato è solo la punta dell’iceberg e gli interessati avranno molto da studiare per gli approfondimenti e le applicazioni. Un’ultima nota: abbiamo fatto riferimento a Ubuntu come la distribuzione che automaticamente imposta un dnsmasq, un bridge e un dhcp all’atto dell’installazione di LXC, ma vi sono altre distribuzioni come OpenSUSE che, attraverso l’installazione del pacchetto yast-lxc , permette di avere un comodo wizard di nome Lxc nel pannello Varie del centro di controllo YaST che aiuta nella procedura di creazione del container e configurazione della rete (bridge, dhcp e dnsmasq, se necessario), procedura naturalmente suggerita ai meno esperti.
Ti potrebbe interessare


")


2 nov 2016