

Il linguaggio è una delle capacità più importanti dell’essere umano per comunicare, apprendere e creare. Tuttavia, il linguaggio non è solo una questione di testo scritto o letto, ma anche di suoni prodotti dalla voce e percepiti dall’orecchio. Per questo motivo, la comprensione e la generazione del linguaggio parlato sono sfide fondamentali per l’intelligenza artificiale, per essere poi applicate in modo efficace in vari ambiti, come l’assistenza personale, l’istruzione, l’intrattenimento e la traduzione. Tuttavia, i modelli esistenti di AI spesso trattano il testo e il parlato come modalità separate e indipendenti, ignorando le loro interazioni e complementarità. Per superare questa limitazione, un team di ricercatori di Google ha presentato AudioPaLM un modello linguistico che può affrontare compiti di comprensione e generazione del linguaggio parlato con maggiore precisione.
AudioPaLM il connubbio di PaLM-2 e AudioLM
AudioPaLM unisce efficacemente i punti di forza di due modelli esistenti: PaLM-2 e AudioLM.
PaLM-2 è un modello linguistico basato sul testo c che eccelle nella comprensione della conoscenza linguistica specifica del testo, rendendolo un completo modello linguistico orientato al testo che Google ha presentato in Google I/O 2023. PaLM-2 si basa su una rete pre-addestrata su grandi quantità di testo in diverse lingue, per la precisione 100, e diversi domini. PaLM-2 può quindi essere adattato a vari compiti basati sul testo, come il completamento del testo, la generazione del riassunto e la traduzione del testo.
AudioLM è un modello linguistico basato sul parlato che dimostra una straordinaria competenza nel mantenere i dettagli paralinguistici come l’identità e il tono del parlante. Anche AudioLM si basa su una rete addestrata su grandi quantità di audio in diverse lingue e domini. AudioLM può quindi essere ideali per tutti quei compiti basati sul parlato, come il riconoscimento vocale, la sintesi vocale da testo e la traduzione vocale da voce. Proprio attraverso la combinazione di questi due modelli si basa AudioPaLM, così che sfrutta l’esperienza linguistica di PaLM-2 e le capacità di conservazione delle informazioni paralinguistiche di AudioLM. Questo si traduce in una comprensione e generazione completa sia del testo che del parlato.
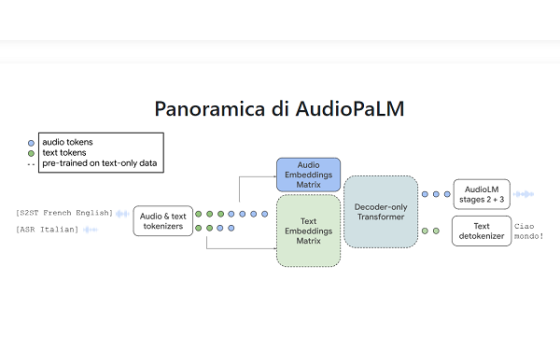
Per facilitare questa integrazione, AudioPaLM utilizza un vocabolario condiviso che può rappresentare sia il parlato che il testo utilizzando un insieme finito di token. Questa unificazione consente a vari compiti, tra cui il riconoscimento vocale, la sintesi vocale da testo e la traduzione vocale da voce, di essere integrati in modo fluido all’interno di una singola architettura e processo di addestramento.
In fase di valutazione, AudioPaLM ha superato i sistemi esistenti nella traduzione vocale da voce con un margine significativo. Ha dimostrato anche che può tradurre con precisione il parlato in testo per diverse lingue, aprendo possibilità per un supporto linguistico più ampio.
Le funzioni di AudioPaLM
AudioPaLM è un modello linguistico innovativo che offre la possibilità di trasferire voci tra lingue diverse con brevi comandi vocali, ma anche ascoltare, parlare e tradurre. Grazie a questa funzione, gli utenti possono comunicare nella lingua che preferiscono, mantenendo le loro caratteristiche vocali distintive, anche se parlano in più lingue. Una delle sue caratteristiche uniche è la capacità di preservare l’identità e l’intonazione del parlante durante la traduzione, anche per le lingue e le combinazioni linguistiche non osservate durante l’addestramento. AudioPaLM può anche trasferire le voci tra le lingue in base a brevi prompt vocali e può catturare e riprodurre voci distinte in diverse lingue, convertire conversazione voce a voce e quella da voce a testo.
Conversazione voce a voce: AudioPaLM è un modello linguistico che ha la capacità di convertire il parlato in parlato preservando la voce del parlante originale anche quando traduce in un’altra lingua. Questa scoperta si basa su test approfonditi sul set di dati CVSS-T, che rappresenta un nuovo punto di riferimento per le traduzioni linguistiche e che migliora l’autenticità della comunicazione tra persone che parlano lingue diverse.
Conversione da voce a testo: AudioPaLM ha ottenuto un grande risultato anche nella traduzione da voce a testo dall’audio originale. Bisogna sottolineare che la traduzione non è un processo univoco, ma possono essere presenti diverse interpretazioni tutte comunque valide, a seconda del contesto e dello scopo. Per ora, AudioPaLM nei risultati finali elaborati non produce la punteggiatura.
Questo lo rende estremamente vantaggioso per le applicazioni di comunicazione multilingue. Inoltre, questa scoperta apre nuove possibilità per le persone che operano in vari contesti linguistiche. Il modello ha infatti una vasta gamma di potenziali in diversi ambiti, per fare degli esempi: assistenti vocali multilingue, servizi di trascrizione automatizzata e qualsiasi altro sistema che abbia bisogno di comprendere o generare linguaggio umano scritto o parlato.
Ti potrebbe interessare





4 lug 2023