
HttTraQt è un programma per il download di interi siti web (statici, solitamente). È fondametalmente la versione modernizzata e cross platform di WinHTTTrack, la sua interfaccia è anche molto simile. Il vantaggio di questa riscrittura è che ora il programma funziona perfettamente su tutti i sistemi operativi. Il programma è molto veloce, e cerca di estrapolare quante più pagine possibili dai siti web. Ovviamente, la piena efficienza si ha solo con i siti web statici, perché i siti dinamici spesso hanno query particolari per raggiungere le pagine web, e HttTraQt non riesce a identificarle. Comunque, il programma cerca di seguire i vari link che trova in ogni pagina già scaricata, per capire se possa trovare altro materiale da scaricare ricorsivamente, quindi si riesce sempre a ottenere una buona quantità dei testi, immagini e altri tipi di file pubblicati su un sito web.
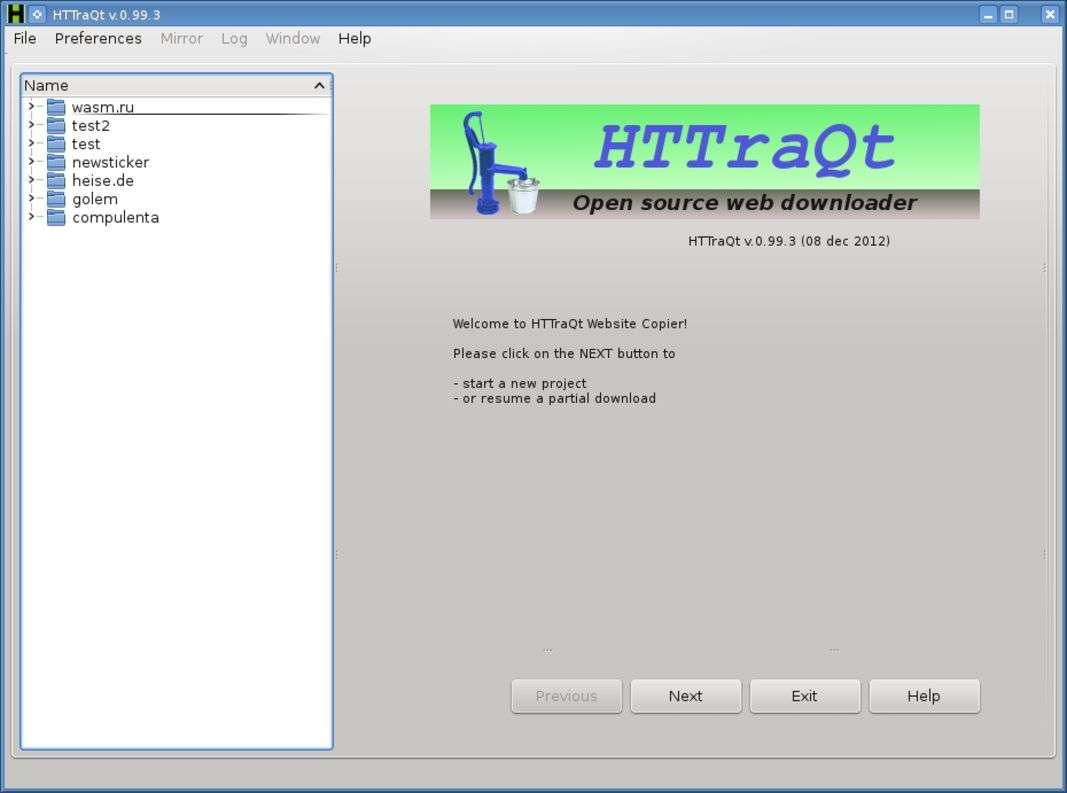
L’interfaccia è pensata come una procedura guidata: per inziare a scaricare un sito web, basta creare un nuovo progetto. Se invece di riapre un progetto già esistente, si può continuare un download interrotto in precedenza. Tutto quello di cui si ha bisogno, per scaricare un sito web, è il suo url completo.
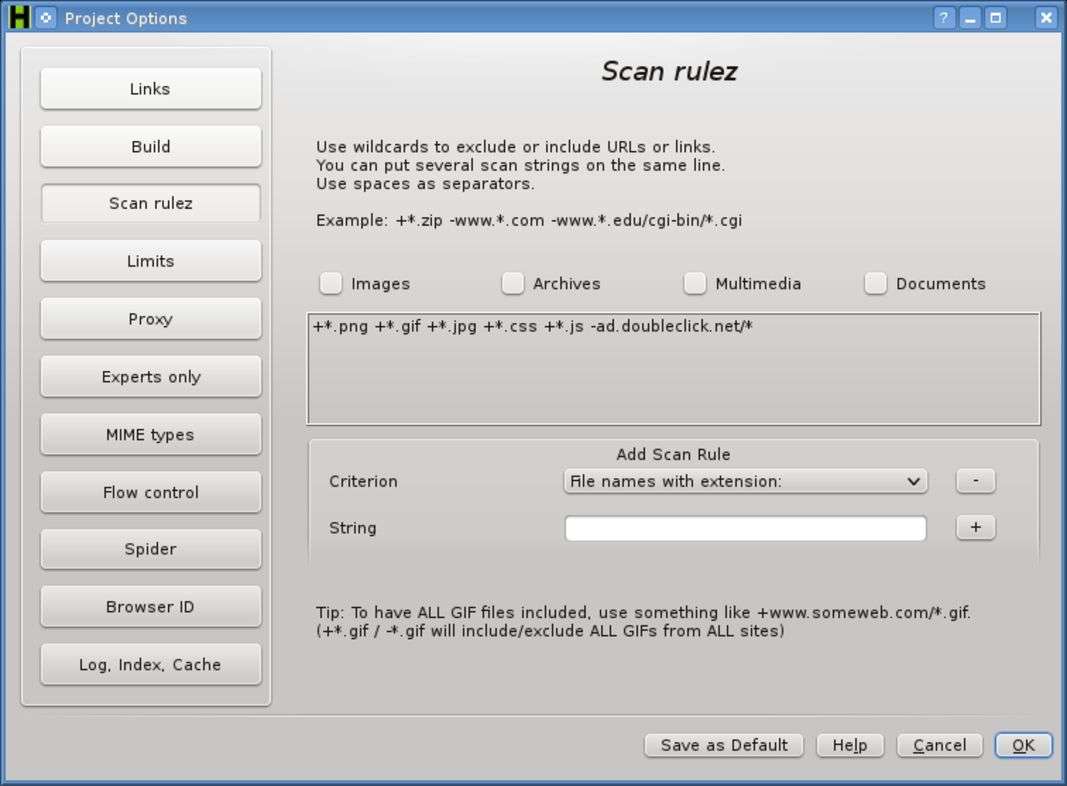
Prima di inziare il download delle pagine è possibile specificare alcuni filtri, in base a ciò che si è interessati a ottenere. Si possono infatti includere o escludere delle estensioni: se si vogliono tutte le immagini di un sito basta selezionre l’apposita casella, altrimenti se si è interessati solo alle Gif basta indicare specificamente quella estensione (*.gif) aggiungendo una regola.
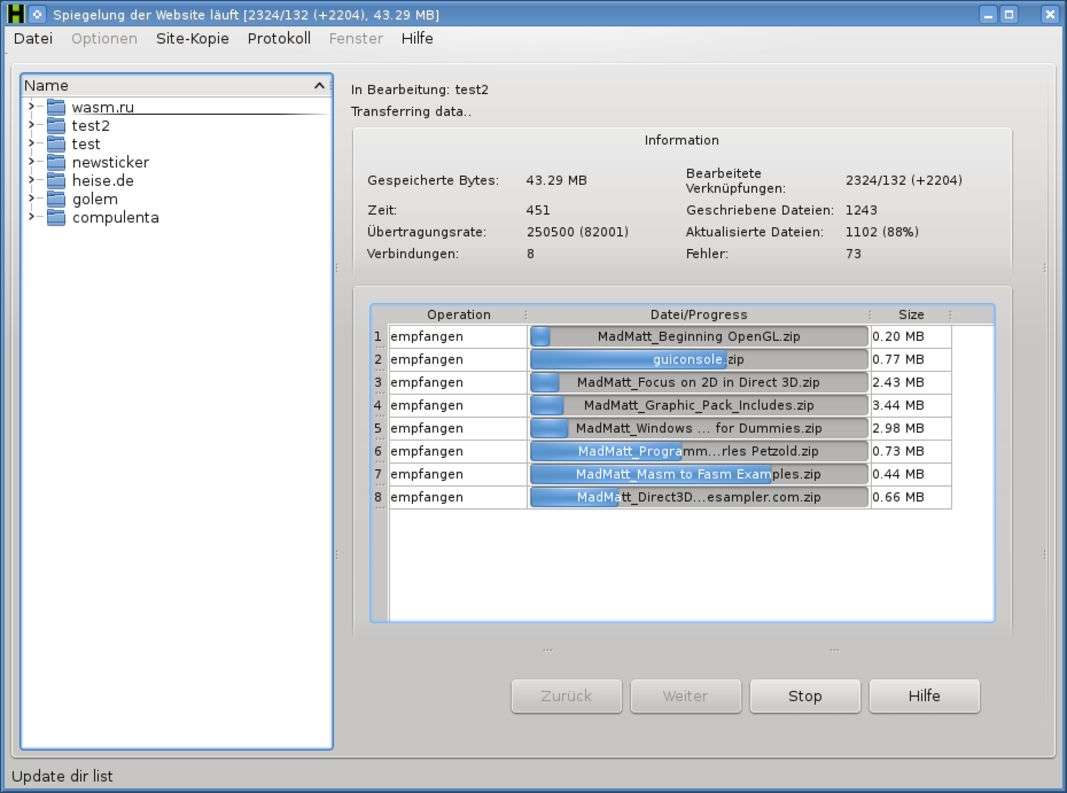
Se l’estensione viene anticipata da un simbolo +, quel tipo di file verrà scaricato. Se viene anticipata da un –, quel tipo di file non verrà scaricato. Se non si indicano regole particolari, tutte le pagine verranno scaricate. All’avvio del download, una serie di barre di progesso indicherà l’andamento dell’operazione: la stima del tempo rimanente non è molto affidabile, perché spesso vengono scoperte nuove pagine man mano che si procede.