
Internet è ricco di informazioni, ma spesso sono contenute in file scomodi da gestire come PDF e HTML o testi formattati. Spesso ci si trova a dover elaborare il materiale per renderlo utilizzabile: un’operazione scomoda e soprattutto noiosa, in particolare per testi molto lunghi. Per fortuna l’operazione può essere automatizzata usando delle espressioni regolari, anche chiamate RegEx : si tratta di sequenze di caratteri speciali che permettono di eseguire ricerche all’interno di un testo senza scrivere tutte le opzioni possibili. Se per esempio si vogliono cercare tutte le occorrenze di un testo in cui si parla di un gatto bisognerebbe cercare le parole “gatto”,”gatti”,”gatta” e “gatte”. Invece, cercando soltanto la RegEx “gatt[oiae]” viene identificata ciascuna delle parole che fanno riferimento al gatto. Per eseguire ricerche e soprattutto sostituzioni all’interno di un testo o una pagina HTML esistono appositi programmi, che però spesso non offrono tutta la flessibilità che si vorrebbe. Inoltre, sviluppare un proprio programma in un linguaggio come Python può essere esagerato per piccoli progetti. Per fortuna esiste un comando del terminale bash dei sistemi GNU/Linux chiamato sed : consente di eseguire sostituzioni utilizzando le RegEx, ed è molto comodo per automatizzare il lavoro grazie alla possibilità di inserirlo in script bash.
Ovviamente è prima di tutto necessario avere un testo di partenza. Il Nuovo Vocabolario di Base (o NVdB) di Tullio De Mauro è stato pubblicato online , e rappresenta un perfetto punto di partenza per provare le tecniche di estrazione dei dati tramite regex.
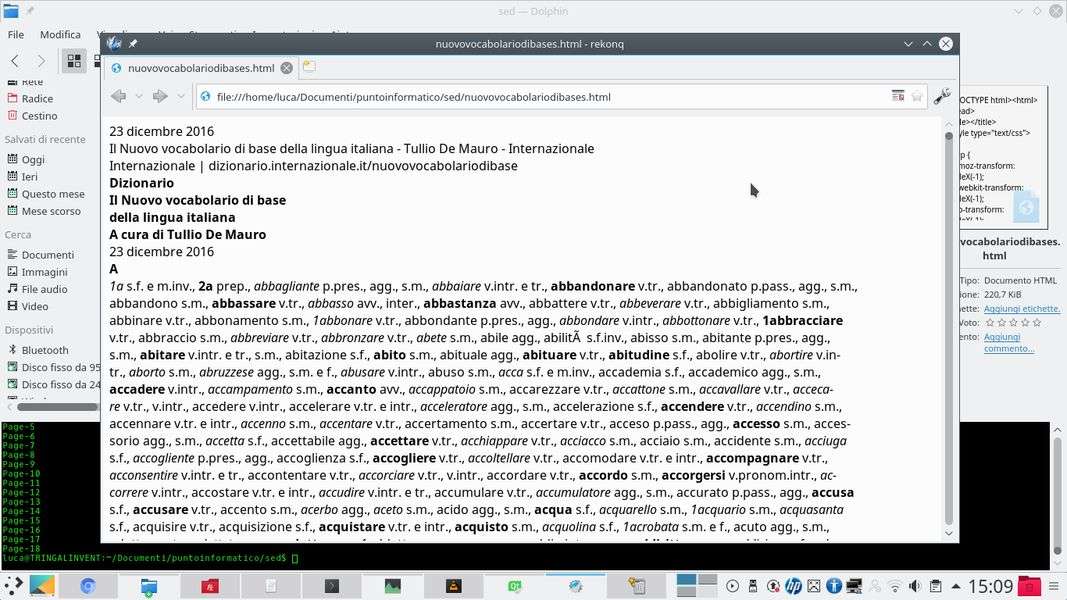
Per lavorare con i nomi può essere una buona idea farsi aiutare dalle variabili della shell bash:
mypdf="nuovovocabolariodibase.pdf"
myfile=${mypdf//.pdf/}
In questo modo alla variabile mypdf viene associato il nome del file PDF, mentre myfile conterrà solo il nome senza estensione. Così è più facile eseguire le modifiche successive. Il PDF può essere trasformato in un file HTML usando il comando:
pdftohtml "$mypdf" "$myfile".html
Il vantaggio del formato HTML è che la formattazione viene mantenuta ed è abbastanza facile da analizzare.
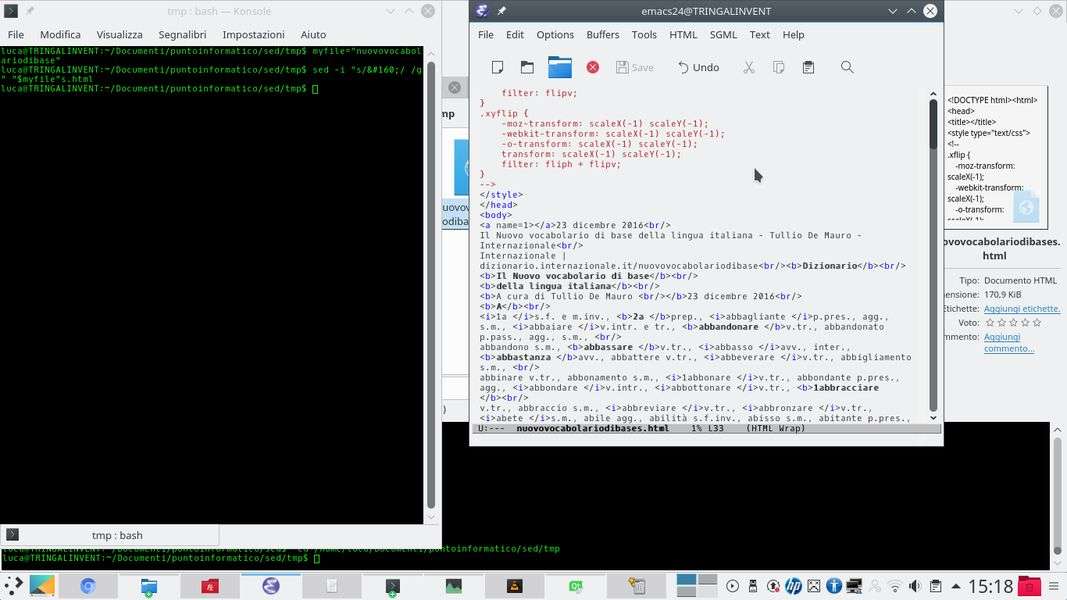
Si può cominciare a fare qualche modifica al file usando sed. Per esempio, sostituendo il simbolo HTML #160 con lo spazio per facilitare la leggibilità:
sed -i "s/ / /g" "$myfile"s.html
La formula di sed per le sostituzioni è molto semplice: s/testo originale/testo nuovo/g . Se non si scrive la g alla fine viene eseguita solo la prima sostituzione. L’argomento -i permette di modificare il file su se stesso, invece di far apparire la versione modificata sul terminale.
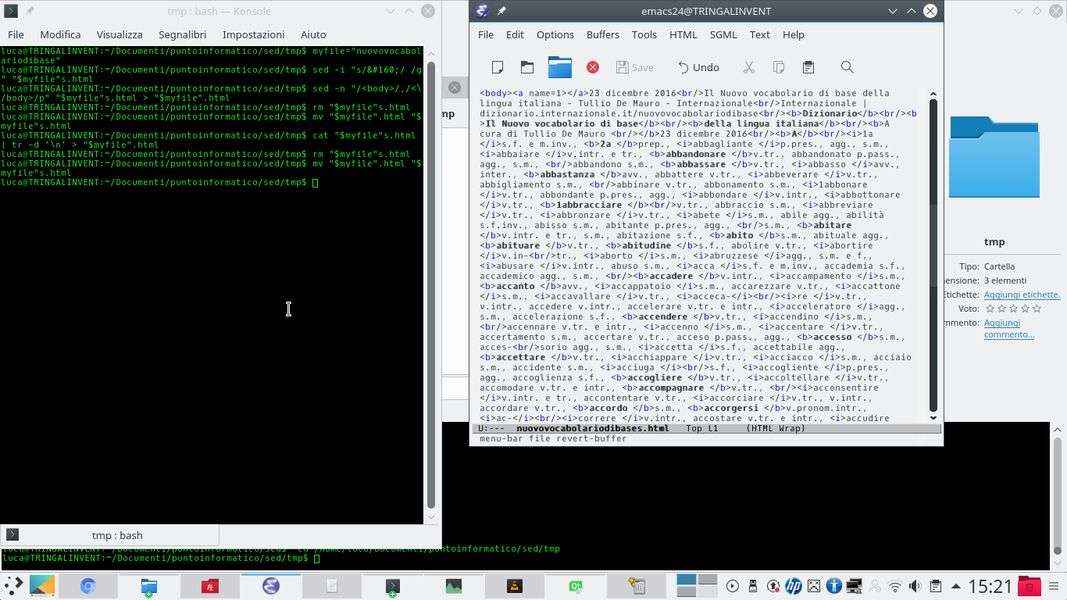
Per l’utilizzo che se ne vuole fare è necessario soltanto il body della pagina HTML. Bisogna quindi estrarre esclusivamente il testo contenuto tra i tag body . Per farlo c’è una formula differente:
sed -n "/<body>/,/</body>/p" "$myfile"s.html > "$myfile".html
rm "$myfile"s.html
mv "$myfile".html "$myfile"s.html
In questo caso non è possibile scrivere sullo stesso file perché viene letto in più volte; bisogna quindi far comparire il testo sul terminale e poi inviarlo ad un file temporaneo con il simbolo > . Alla fine, il file viene sostituito all’originale con il comando mv . L’argomento -n di sed permette di avere un risultato più pulito, scrivendo tutto il testo risultante in una sola volta invece che procedendo una linea per volta. Questo è importante quando si estrae del testo.
C’è poi un altro dettaglio importante: sed legge una sola riga alla volta. Però le righe sono state generate in modo disordinato durante la conversione del PDF, è bene quindi eliminare tutti i caratteri di nuova riga n in modo da avere l’intero testo su un’unica riga. Non si può fare direttamente in sed, proprio perché per sua natura gestisce ogni riga come separata, ma lo si può fare con il comando tr e con cat :
cat "$myfile"s.html | tr -d 'n'>"$myfile".html
rm "$myfile"s.html
mv "$myfile".html "$myfile"s.html
Anche in questo caso si usa un file temporaneo e poi lo si muove al posto di quello originale.
Nel Nuovo Vocabolario di Base le parole sono riunite in base alla lettera iniziale, scritta a caratteri cubitali prima di ogni blocco di parole. Ma questo non va bene se si vuole realizzare una tabella, quindi si possono rimuovere in questo modo:
sed -i "s/<b>[QWERTYUIOPASDFGHJKLZXCVBNM]</b><br/>/, /g" "$myfile"s.html
Come si riconoscono le iniziali? Si tratta di una qualsiasi lettera maiuscola racchiusa tra due tag b seguito dal tag br . E bisogna sostituirle con una virgola e uno spazio. Le parentesi quadre significano che può essere presente una qualsiasi delle lettere all’interno. È importante notare che il simbolo / deve essere preceduto dal carattere di escape . Quindi invece di / si deve scrivere / , perché il solo / ha un preciso significato.
Se la porzione di testo da rimpiazzare è molto lunga si può usare una variabile, scrivendo:
newpage='dizionario.internazionale.it/nuovovocabolariodibase<br/>[0123456789]*<br/><hr/><a name=[0123456789]*></a>23 dicembre 2016<br/>Il Nuovo vocabolario di base della lingua italiana - Tullio De Mauro - Internazionale<br/>'
sed -i "s/${newpage}//g" "$myfile"s.html
In questo caso la variabile si chiama newpage e contiene tutto il testo che il NVdB inserisce tra una pagina e l’altra. Buona parte del testo è costante, ma il numero della pagina cambia ogni volta: non è un problema, perché sappiamo che si tratta di una semplice sequenza di cifre, quindi si può rappresentare con la regex [0123456789]* in modo da far sapere a sed che si vuole identificare un qualsiasi numero. L’asterisco immediatamente dopo le parentesi significa che una qualsiasi di quelle cifre può essere ripetuta una o più volte.
Per cancellare un testo basta sostituirlo con “il nulla”, cioè scrivere direttamente //g come finale del comando di sed.
Per finire, si può usare anche sed per trasformare tutto il testo in lettere minuscole, per semplificarsi la vita d’ora in poi:
sed -i 's/.*/L&/g' "$myfile"s.html
Il simbolo . rappresenta un carattere qualsiasi, mentre l’asterisco significa che tale carattere può essere ripetuto più volte. Dunque, .* significa “tutti i caratteri del testo”. La sequenza speciale L& indica che il carattere identificato va reso minuscolo. Ciò evita di dover considerare ogni singola lettera per applicarle la trasformazione in minuscolo, e permette di farlo in un attimo a tutto il testo.
Nel NVdB vi sono molte parole spezzate, perché quando una parola è troppo lunga viene mandata a capo riga con il classico trattino. Per riunire le parole spezzate basta eliminare sia il trattino che l’eventuale formattazione inutile (il tag br indica la nuova riga in HTML):
sed -i "s/-<br/>//g" "$myfile"s.html
sed -i "s/-</b><br/><b>//g" "$myfile"s.html
sed -i "s/-</i><br/><i>//g" "$myfile"s.html
C’è poi un altro dettaglio: a causa dei problemi nella formattazione del NVdB può capitare che alcune parole vengano spezzate perché salta una consonante doppia. Per esempio, alluminio può in realtà comparire come al uminio , e questo è un problema; che però si può risolvere sfruttando uno degli strumenti più utili delle regex: la divisione in blocchi con i simboli ( e ) :
sed -i "s/([rtpsfglzcvbnm]) ([aeiouèéòàùì])/112/g" "$myfile"s.html
In questo modo si dice a sed che ogni volta in cui si trova una qualsiasi consonante (primo blocco) e una qualsiasi vocale (secondo blocco, si considerano anche gli accenti) separate da uno spazio, ci si ritrova in questa situazione. Infatti, in italiano le parole non terminano per consonante, uno spazio in quel punto non avrebbe senso. Questa situazione va risolta scrivendo di nuovo il primo blocco (cioè 1 ) per due volte, seguito poi dal secondo blocco (cioè 2 ). In altre parole: l a diventa lla , mentre t ì diventa ttì . Con una sola regex sono state risolti centinaia di errori di impaginazione.
Ora si può dividere nuovamente il testo in righe, dedicandone una ad ogni parola come in una tabella:
sed -i "s/<br/>//g" "$myfile"s.html
sed -i "s/, ([qwertyuiopasdfghjklzxcvbnm.1234567890]*)./; 1./g" "$myfile"s.html
sed -i "s/,/n/g" "$myfile"s.html
La prima cosa da fare è sostituire gli attuali tag br della pagina HTML con degli spazi, perché gli invii a capo (per l’appunto i tag br ) sono messi un po’ a caso. Poi si devono riconoscere le varie definizioni grammaticali: per esempio una parola può essere sia sostantivo che aggettivo, quindi viene indicata come agg., sost. . Queste virgole sono un problema, ma si possono sostituire con una regex: in tutti questi casi si ha sempre le sequenza virgola, spazio, insieme di lettere numeri o un punto (che richiede l’escape, quindi è . perché è un carattere speciale), e infine un altro punto. Nell’esempio agg., sost. , la regex trova il testo , sost. e molto banalmente lo sostituisce con ; sost. . In altre parole, queste virgole vengono sostituite da un puntovirgola, ma soltanto queste: le altre virgole rimangono dove sono.
Infatti, le altre virgole sono quelle che separano una parola dall’altra, e quindi quelle che devono distinguere le righe della tabella. Basta sostituire tutte le virgole in caratteri n , cioè in invio a capo riga (tranne ovviamente quelle virgole che ormai non ci sono più perché le abbiamo già trasformate in punto virgola).
Basta pensare alla parola abbagliante : se non avessimo fatto la sostituzione delle prime virgole il testo
abbagliante p.pres., agg., s.m., abbaiare
sarebbe diventato
abbagliante p.pres.
agg.
s.m.
abbaiare
mentre grazie all’uso del blocco, con le parentesi ( e ) si ottiene il risultato:
abbagliante p.pres.; agg.; s.m.
abbaiare
Prima di procedere con la corretta divisione del testo in colonne per la tabella, bisogna pulire le parti inutili:
sed -i "s/<body>.*23 dicembre 2016/ /g" "$myfile"s.html
sed -i "s/dizionario.internazionale.it/nuovovocabolariodibase[0123456789]*<hr/></body>//g" "$myfile"s.html
Anche in questo caso semplici regex permettono di cancellare tutto il testo che si trova prima e dopo l’elenco delle parole.
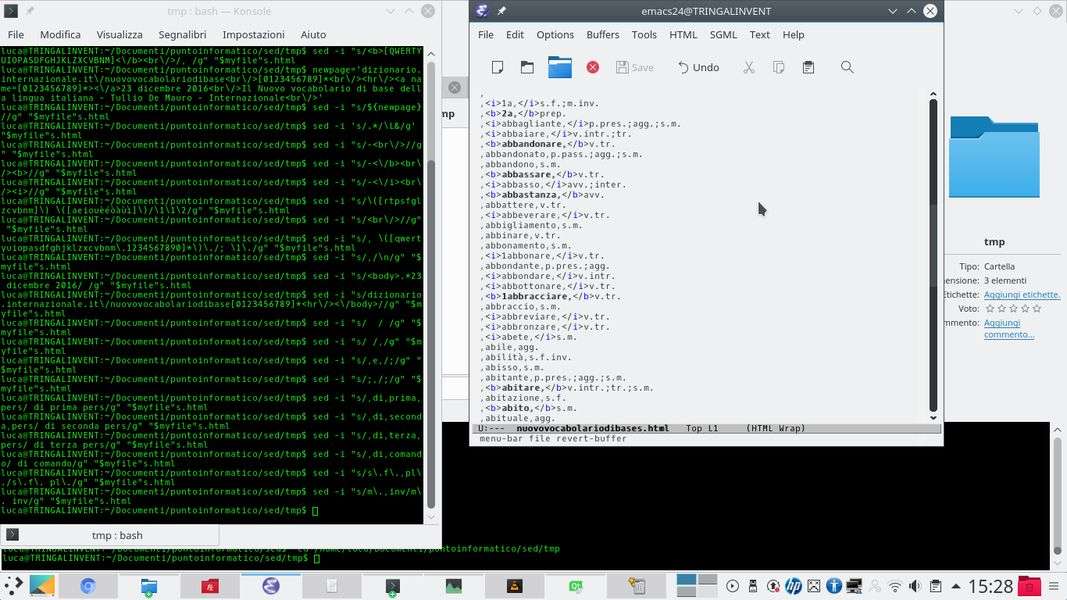
La divisione in colonne è un po’ più lunga da ottenere, ma più che altro a causa di alcune particolarità nella scrittura del Nuovo Vocabolario di Base:
sed -i "s/ / /g" "$myfile"s.html
sed -i "s/ /,/g" "$myfile"s.html
sed -i "s/,e,/;/g" "$myfile"s.html
sed -i "s/;,/;/g" "$myfile"s.html
Prima si sostituiscono gli eventuali doppi spazi con uno spazio singolo, per evitare doppioni inutili. Poi si possono sostituire gli spazi con virgole, che saranno i separatori di colonna. Ricordiamo che finora non esistevano virgole perché erano state trasformate tutte in invii a capo riga. Si puliscono le eventuali forme ,e, e ;, , dovute al fatto che il NVdB non scrive sempre allo stesso modo le caratteristiche grammaticali di ogni parola.
Alla fine, si devono correggere alcune diciture:
sed -i "s/,di,prima,pers/ di prima pers/g" "$myfile"s.html
sed -i "s/,di,seconda,pers/ di seconda pers/g" "$myfile"s.html
sed -i "s/,di,terza,pers/ di terza pers/g" "$myfile"s.html
sed -i "s/,di,comando/ di comando/g" "$myfile"s.html
sed -i "s/s.f.,pl./s.f. pl./g" "$myfile"s.html
sed -i "s/m.,inv/m. inv/g" "$myfile"s.html
sono poche e piuttosto irregolari: si potrebbe scrivere una sola regex per gestirle tutte, ma non ha molto senso; tanto vale sostituirle una per una. I punti devono sempre essere preceduti dal simbolo di escape , altrimenti sed li considererà come rappresentati di un qualsiasi carattere.
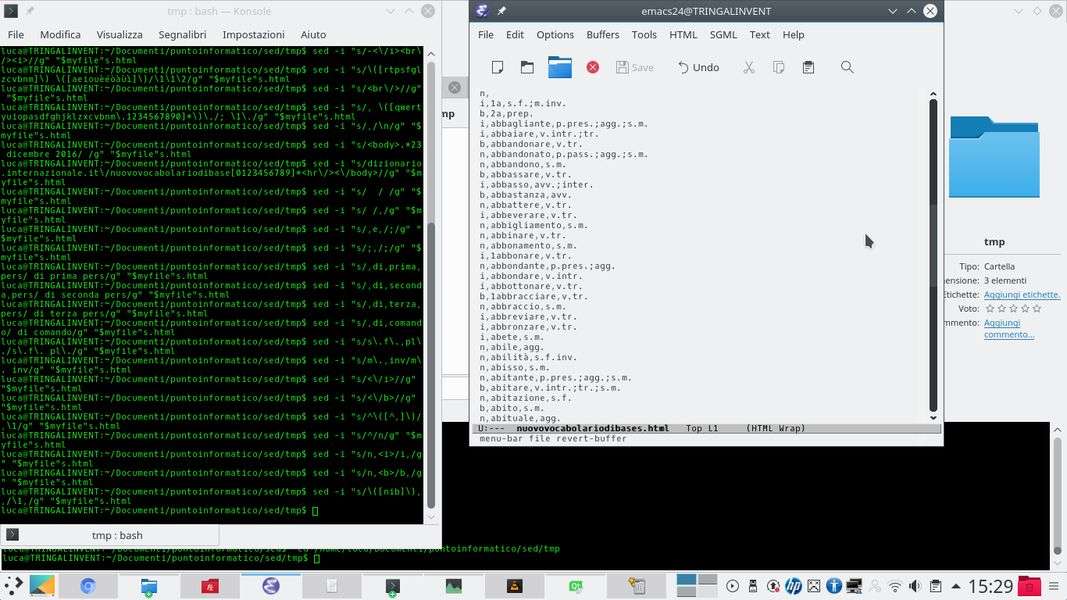
Come ultima operazione si aggiunge un’apposita colonna per riconoscere le formattazione. Infatti, le parole possono essere non formattate, in grassetto (bold, tag b ) o in corsivo (italic, tag i ), e questa formattazione distingue delle categorie di parole. Si potrebbero tenere i tag HTML, ma sono scomodi: per una tabella è molto meglio creare una colonna dedicata in cui memorizzare la formattazione di ogni parola. Si può cominciare così:
sed -i "s/</i>//g" "$myfile"s.html
sed -i "s/</b>//g" "$myfile"s.html
Prima si cancellano i tag di chiusura, cioè /i e /b . Poi si deve procedere a ripulire dai tag l’inizio di ogni riga aggiungendo la colonna per la formattazione:
sed -i "s/^([^,])/,1/g" "$myfile"s.html
sed -i "s/^/n/g" "$myfile"s.html
Se la riga comincia (il simbolo ^ indica l’inizio della riga) con un blocco costituito da un carattere che non è la virgola (il simbolo ^ dentro parentesi quadre è una negazione, quindi [^,] significa qualsiasi carattere tranne la virgola), allora la si riscrive in modo che quel primo carattere venga anticipato proprio da una virgola. Ora, quindi, ogni riga inizia con una e una sola virgola. A questo punto si può premettere la lettera n , che utilizzeremo come simbolo per indicare una parola non formattata.
sed -i "s/n,<i>/i,/g" "$myfile"s.html
sed -i "s/n,<b>/b,/g" "$myfile"s.html
sed -i "s/([nib]),,/1,/g" "$myfile"s.html
In questo momento tutte le righe iniziano con la dicitura n, mentre per il nostro scopo quelle con parole in grassetto dovrebbero cominciare con b, e quelle in corsivo con i, . Basta sostituire i tag con il simbolo giusto per la prima colonna. Alla fine, come ultima sostituzione, puliamo le eventuali virgole. Ogni riga inizia infatti con un blocco che può essere costituito da una qualsiasi delle lettere nib , ma alcune righe a causa di errori di scrittura potrebbero essere seguite non da una virgola, ma da due virgole. Quindi manteniamo costante la prima lettera (è il blocco 1 tra le parentesi () ), ma se necessario sostituiamo le due virgole con una sola virgola.
Il testo HTML originale è quindi diventato una semplice tabella del tipo:
i,abbaiare,v.intr.;tr.
b,abbandonare,v.tr.
n,abbandonato,p.pass.;agg.;s.m.
Quindi la prima colonna contiene la formattazione della parola, la seconda colonna contiene la parola e la terza contiene le varie caratteristiche grammaticali possibili separate da punto e virgola.
Volendo, è anche possibile eseguire un ultimo comando del tipo:
sed '1d' "$myfile"s.html>"$myfile".csv
per eliminare la prima riga del file, visto che è quella normalmente rimasta vuota dopo la pulizia dell’intestazione.
Il codice completo, riunito in uno script bash, si può trovare su github .