
Navigare sulla Rete è una delle attività più comuni, lo si fa continuamente anche mentre si svolgono altre attività. Per esempio, se ci si è dimenticati qualcosa si può andare un attimo sul Web e cercare l’informazione di cui si ha bisogno. Quando si lavora in un ambiente grafico è possibile usare diversi browser, i più famosi sono certamente Firefox e Chromium. Ma se si sta lavorando da terminale, magari mentre si fa la manutenzione di un server o un semplice Raspberry Pi, e non si dispone di un ambiente grafico? Per questo esiste w3m , un browser Web che funziona ad interfaccia di testo. Naturalmente ci possono essere anche altri motivi per utilizzare un browser senza ambiente grafico, oltre alla necessità: il browser è infatti molto rapido e non carica alcun contenuto in Flash. Quindi, niente popup o applicazioni fastidiose e pericolose per la privacy. Il browser w3m, inoltre, offre diverse opzioni utili per sviluppatori e scrapers . Per fare un esempio, w3m consente la ricerca all’interno della pagine Web con le RegEx , quindi chi sa come utilizzarle può eseguire ricerche anche molto complesse.
Per installare w3m servono i pacchetti w3m e w3m-img . Il secondo permette la visualizzazione di immagini usando il server X oppure il framebuffer Linux (che quindi funziona anche su sistemi dotati soltanto di interfaccia a riga di comando). Il programma può poi essere aperto fornendogli almeno un indirizzo da cui partire. Ad esempio, con il comando w3m google.it si visualizza Google Italia.
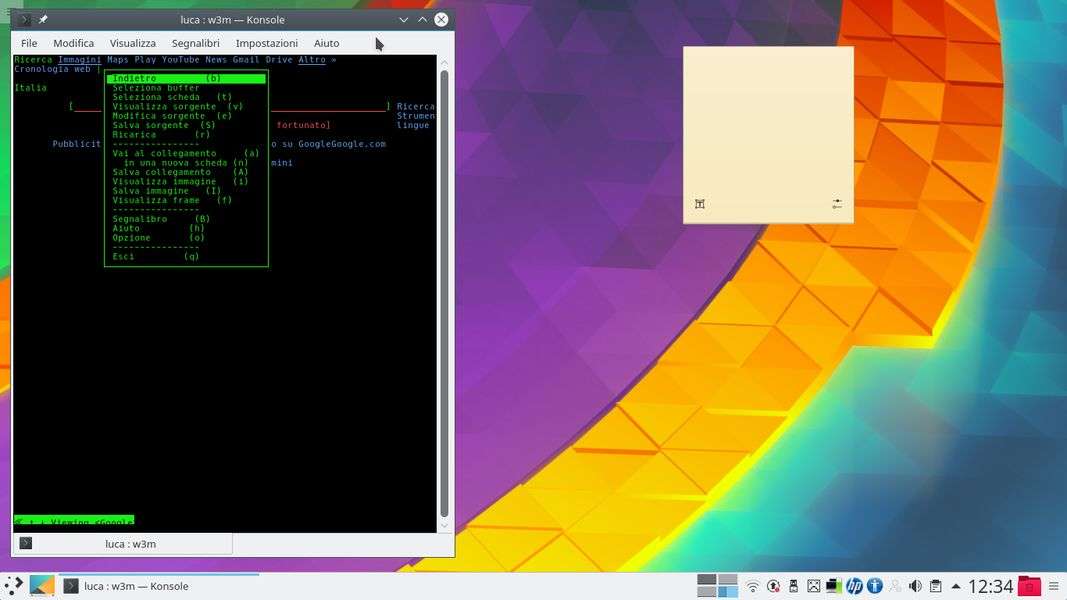
Se ci si trova in un ambiente che riconosce il mouse, è possibile cliccare su un qualsiasi punto della pagina Web visualizzata per vedere un menu con le opzioni principali. Se non si usa il mouse è comunque possibile spostarsi nella pagina con le frecce direzionali. Per esempio, spostando il cursore su un link e premendo il tasto Invio si apre il link.
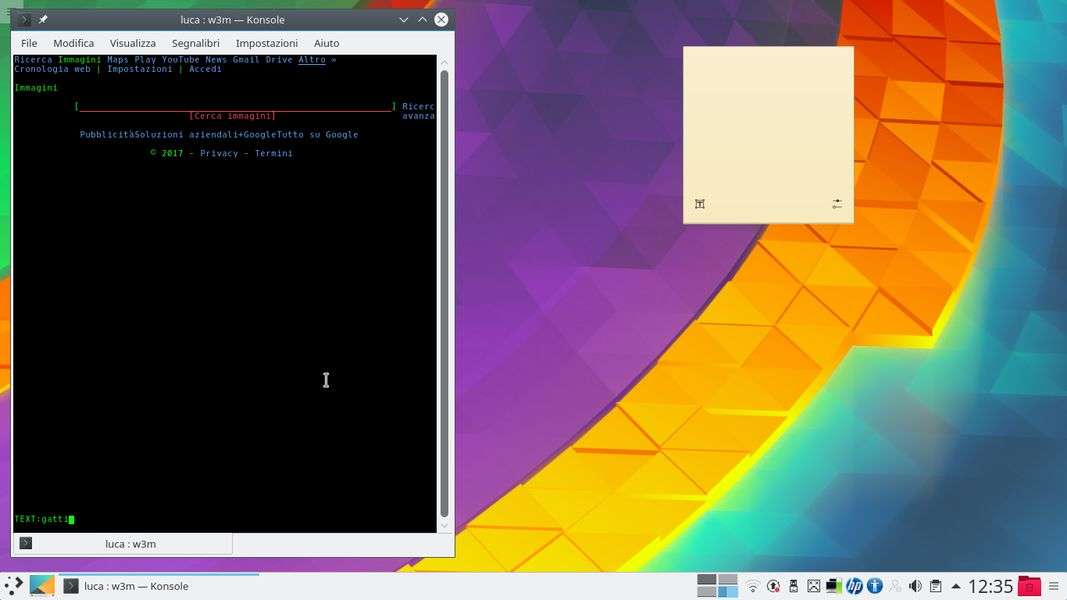
È anche possibile passare ai vari elementi notevoli della pagina come link, caselle di testo e immagini, usando il tasto Tab . Quando si arriva con il cursore su una casella di testo si può premere Invio e cominciare a scrivere. Per esempio, nella casella di ricerca di Google Images si può digitare il testo che si desidera cercare. Per confermare basta dare di nuovo Invio . Nel caso della ricerca di Google, naturalmente, si deve poi spostare il cursore sul pulsante [Cerca] e premere Invio per iniziare la ricerca.
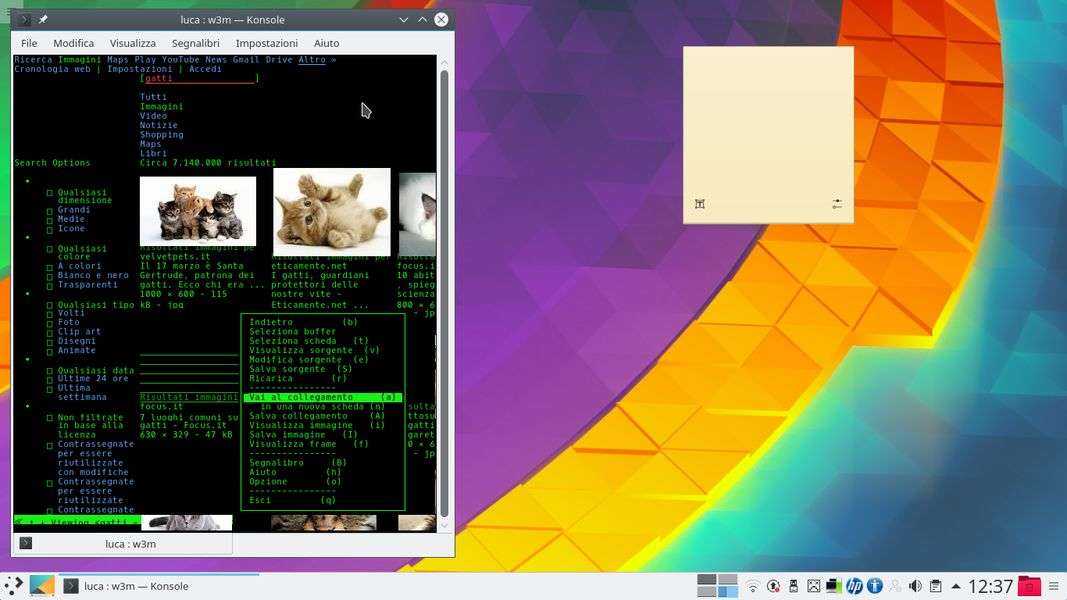
Le immagini vengono visualizzate, se possibile, direttamente all’interno della pagina. Quando ci si sposta è possibile scegliere una serie di opzioni:
T: apre una nuova scheda
b: torna alla pagina precedente
U: vai a un URL (da specificare)
u: mostra l'URL del link selezionato
n: apre il link selezionato in una nuova scheda
i: mostra l'URL dell'immagine selezionata
Esc+I: scarica l'immagine selezionata
Il browser w3m, infatti, consente l’utilizzo di più schede: per aprirne una nuova basta premere T e poi U per poter digitare l’indirizzo che si desidera visitare.
Per passare da una scheda all’altra si può semplicemente cliccare su una di esse, oppure utilizzare i simboli { e } (rispettivamente AltGr+7 e AltrGr+0) per andare indietro e avanti con le varie schede. Un altro modo, molto semplice, per spostarsi tra le varie schede aperte è premere Esc+t . Viene visualizzato un menu che permette di passare da una scheda all’altra con le frecce e scegliere se visualizzarla premendo Invio o chiuderla premendo D . La scheda attuale può anche essere chiusa premendo Ctrl+q . Attenzione, però: premendo soltanto q si chiude il programma.
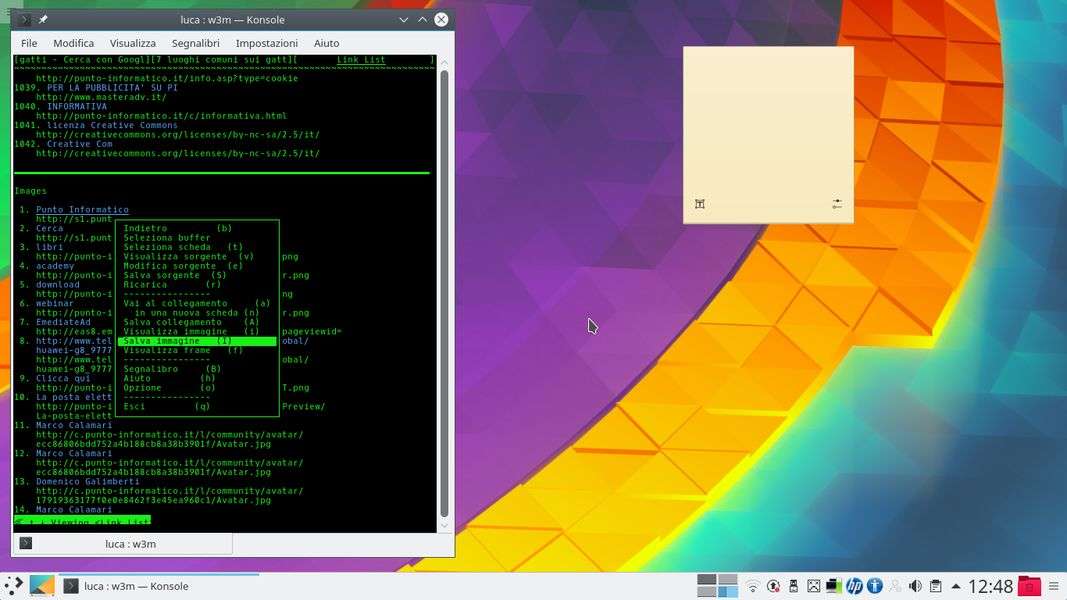
Vi sono anche delle opzioni estremamente utili per i programmatori, e in generale per chiunque voglia fare scraping:
L: mostra un elenco di tutti i link e le immagini presenti nella pagina web
S: salva tutto il buffer visualizzato in un file
v: visualizza il codice sorgente della pagina
Ctrl+S: cerca un testo all'interno della pagina
Ctrl+k: mostra i cookies della pagina web
L’opzione L è comoda perché la lista che si ottiene può essere memorizzata in un file (premendo S ), quindi si può copiare tutto l’elenco dei link e delle immagini per poi scaricare i file automaticamente con uno script wget . In questo modo si lavora con un elenco di link già ripulito da tutte le parti inutili della pagina web. Se si vuole cercare qualcosa nella pagina basta premere Ctrl+S , digitare il testo da cercare e premere Invio . Per ripetere la stessa ricerca basta premere due volte Ctrl+S . Interessante il fatto che la ricerca possa essere fatta con le regex.