

Ponendo la stessa domanda a chatbot basati su diversi modelli IA, si ottengono risposte differenti. Da un certo punto di vista, questo può essere interpretato come il risultato di una differenziazione dei servizi. E fin qui, nulla di male. Dipende in primis dalla natura dei dati impiegati durante la fase di addestramento. La conseguenza, quasi inevitabile, è che però, su alcuni temi in particolare, le repliche possano essere affette da bias. Se in gioco ci sono le visioni della politica, per loro stessa definizione discusse e controverse, la questione di fa delicata. Vale altrettanto per l’informazione e la disinformazione.
Sinistra e destra: da che parte stanno i modelli IA?
Una ricerca condotta in collaborazione tra University of Washington, Carnegie Mellon University e Xi’an Jiaotong University ha preso in esame 14 diversi modelli di intelligenza artificiale, sottoponendo loro richieste a proposito di argomenti come democrazia e femminismo. Sono state poi analizzate le reazioni, per arrivare ad associarle a una o all’altra posizione, arrivando infine a disegnare il grafico qui sotto.
L’ascissa è associata fattore sociale, variando da un approccio libertario a uno autoritario. L’ordinata, invece, a quello economico, identificandolo come più vicino a un ideale di sinistra oppure di destra.
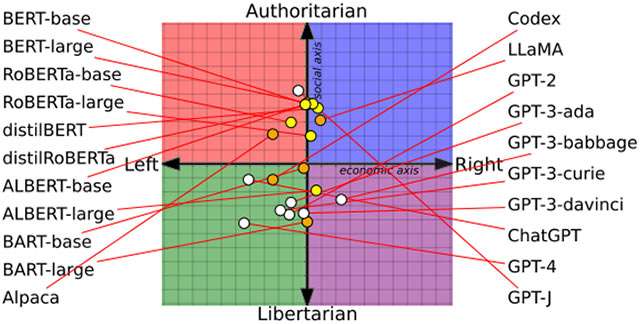
Dalla media, è risultato che GPT-4 di OpenAI, oggi alla base di ChatGPT (per gli utenti Plus) e, in una sua versione personalizzata ad hoc, al nuovo Bing di Microsoft, abbia fornito risposte classificate come più vicine a una posizione libertaria di sinistra. LLaMA di Meta, invece, a una autoritaria di destra.
Algoritmi, diritti e sensibilità
La ricerca è stata strutturata in tre fasi. Nella prima, ai 14 modelli è stato chiesto di dichiararsi in accordo o in disaccordo con 62 affermazioni relative al mondo politico. Durante la seconda, i ricercatori hanno dato in pasto a GPT-2 e RoBERTa (quest’ultimo di Meta) alcuni dataset creati partendo dagli articoli della stampa e dai post sui social network di fonti riconducibili all’una e all’altra fazione politica, così da capire se la fase di addestramento abbia una qualche influenza sui bias. Test condotto con esito affermativo. Il terzo e ultimo step è quello che ha permesso di accertare come le differenti inclinazioni rilevate abbiano effetto sul processo di classificazione dei contenuti riconducibili a disinformazione e incitamento all’odio.
In estrema sintesi, i modelli di sinistra hanno dimostrato una maggiore sensibilità su temi come i diritti della comunità LGBTQ+, nera e delle minoranze religiose, mentre quelli di destra verso gli uomini bianchi di fede cristiana.
L’articolo in cui lo studio è stato descritto nel dettaglio è stato premiato il mese scorso dall’Association for Computational Linguistics. Chi lo desidera, può consultare la sua versione integrale in PDF.
Ti potrebbe interessare





8 ago 2023