

Quando nel 2020 il team di Mark Zuckerberg ha iniziato a spostare le proprie ambizioni verso quello che oggi prende il nome di Metaverso, il gruppo ha compreso la necessità di mettere a punto un centro ad alta potenza computazionale da poter mettere al servizio di questa nuova frontiera. Nasceva in quei giorni un progetto che ora il gruppo è in grado di svelare e che sarà completato entro la metà del 2022: si tratta dell’AI Research SuperCluster (RSC), ossia il supercomputer targato Meta che già oggi promette di essere il maggior supercomputer per l’Intelligenza Artificiale mai sviluppato.
AI Research SuperCluster (RSC)
760 NVIDIA DGX A100, per un totale di 6080 GPU con 175 petabyte di Pure Storage FlashArray e 46 petabyte di cache e 10 petabyte di Pure Storage FlashBlade: questo quanto posto in essere durante la “Fase 1”, con la “Fase 2” già in essere per arrivare a 16000 GPU come obiettivo finale.
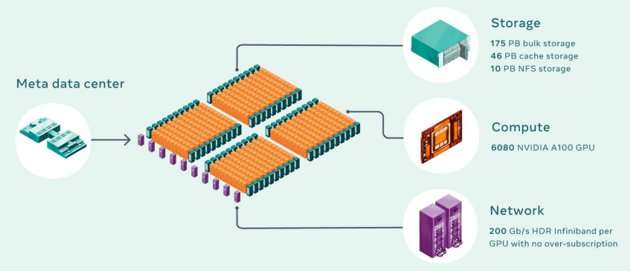
Per meglio capire il grado di potenza disponibile, Meta spiega che un modello con decine di miliardi di parametri potrà essere elaborato in tre settimane rispetto alle 9 settimane che servivano in precedenza. Non si tratta soltanto di accelerare: “ci aspettiamo che questo passo in avanti cambi non soltanto le capacità di creare modelli di IA più accurati per i nostri servizi di oggi, ma anche di abilitare esperienze completamente nuove, in modo particolare nel Metaverso.
Un investimento di lungo periodo, insomma, ma con una direzione ben precisa:
Meta sottolinea come la scommessa su progetti di questo tipo non possa ammettere compromessi: le performance sono l’unico obiettivo da poter perseguire. Tutto ciò è però avvenuto durante mesi di isolamento, di lavoro da remoto e di grandi difficoltà sul mercato dei chip. Ciò ha moltiplicato oltremodo le difficoltà di realizzazione del progetto, ma tutto sta ora arrivando a compimento e, anzi, le prime unità sarebbero già attive su modelli applicati al linguaggio naturale e sulla computer vision.
Speriamo che RSC possa aiutarci a costruire nuovi sistemi di Intelligenza Artificiale che possano, ad esempio, abilitare la traduzione in tempo reale della voce per grandi gruppi di persone, ognuna che parla un linguaggio differente, così che possano collaborare su un progetto di ricerca o giocare insieme.
[gallery_embed id=271426]
Il supercomputer è in grado di servire oggi 16TB di dati al secondo, ma l’obiettivo è di salire a 1 exabyte in prospettiva. Si va oltre il semplice concetto di “Big Data”: l’orizzonte è il Metaverso e con una strada tanto lunga da affrontare è necessario avere quanta più potenza a disposizione e quanti più dati da poter elaborare, così da poter alzare l’asticella rispetto a quello che è oggi possibile immaginare nell’attuale perimetro dell’IA.
Ti potrebbe interessare





24 gen 2022