

Meta ha annunciato un importante passo in avanti per il mondo dell’IA: come illustrato da Yann LeCun, Vice-President e Chief AI Scientist del gruppo, il rilascio del nuovo modello Video Joint Embedding Predictive Architecture (V-JEPA) consentirà infatti all’IA di comprendere meglio il mondo fisico, le interazioni tra gli oggetti ed una serie di implicazioni che permetteranno di ottenere risultati più realistici, più credibili, più affidabili.
V-JEPA, verso un’IA più intelligente
L’apprendimento attraverso l’osservazione gioca un ruolo cruciale nello sviluppo della nostra comprensione del mondo. Sin dalla tenera età, umani e animali apprendono le leggi fondamentali della fisica semplicemente osservando gli effetti delle proprie azioni sull’ambiente circostante. La capacità di assorbire conoscenza osservando e interagendo con il mondo è ora alla base anche dell’approccio innovativo adottato da Meta nella realizzazione del modello di intelligenza artificiale avanzata V-JEPA. Anche l’IA, insomma, potrà imparare osservando.
Secondo Yann LeCun, Vice Presidente e Chief AI Scientist di Meta, il modello Joint Embedding Predictive Architectures (JEPA), introdotto nel 2022, segna un passo avanti significativo nella ricerca di un’intelligenza artificiale che impara in modo simile agli esseri umani. Il modello V-JEPA, in particolare, rappresenta un’evoluzione nel campo dell’IA, in grado di prevedere e pianificare azioni in modo più generalizzato ed efficiente.
Il nostro obiettivo è costruire un’intelligenza automatizzata avanzata in grado di apprendere come gli esseri umani, realizzando modelli interni del mondo che ci circonda per apprendere, adattarsi e creare efficientemente piani adeguati allo svolgimento di compiti complessi
Yann LeCun
V-JEPA si distingue per la sua metodologia non generativa, apprendendo attraverso la previsione di elementi mancanti in video all’interno di uno spazio di rappresentazione astratto. Questo approccio differisce significativamente dalle tecniche generative tradizionali, offrendo una maggiore flessibilità e un’efficienza di addestramento notevolmente superiore. L’auto-supervisione permette a V-JEPA di essere pre-addestrato senza l’uso di dati etichettati, rendendo l’apprendimento più efficiente e versatile.
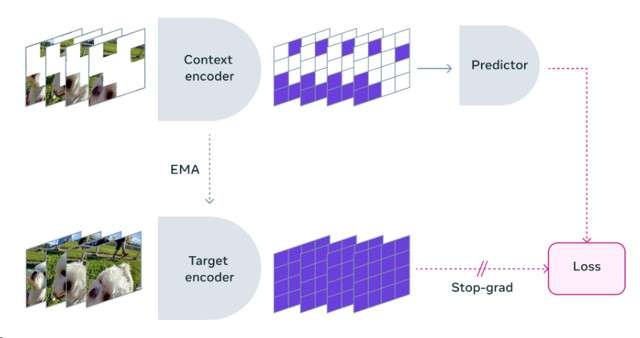
Una delle caratteristiche più innovative di V-JEPA è la sua capacità di fare previsioni efficienti, concentrando l’attenzione su informazioni concettuali di alto livello piuttosto che su dettagli irrilevanti. Questo aspetto è cruciale per applicazioni future, come l’assistenza AI contestuale per dispositivi di realtà aumentata, dove la comprensione del contesto gioca un ruolo fondamentale.
V-JEPA è un modello non generativo che apprende prevedendo le parti mancanti o mascherate di un video in uno spazio di rappresentazione astratto. Il processo è simile a quello della nostra Image Joint Embedding Predictive Architecture (I-JEPA), che confronta le rappresentazioni astratte delle immagini, piuttosto che confrontare i pixel. A differenza degli approcci generativi che tentano di riempire ogni pixel mancante, V-JEPA ha la flessibilità necessaria per scartare informazioni imprevedibili, il che porta a un miglioramento dell’addestramento e dell’efficienza del campione di un fattore compreso tra 1,5x e 6x.
Poiché adotta un approccio di apprendimento auto-supervisionato, V-JEPA viene pre-addestrato interamente con dati privi di etichette. Le etichette vengono utilizzate solo per adattare il modello a un compito particolare dopo la prima fase di addestramento. Questo tipo di architettura si rivela più efficiente dei modelli precedenti, sia in termini di volume necessario di esempi etichettati, sia in termini di sforzo totale dedicato all’apprendimento, anche dei dati non etichettati. Con V-JEPA abbiamo riscontrato una maggiore efficienza su entrambi i fronti.
L’approccio multimodale, che integra l’audio alle immagini, rappresenta il prossimo passo evolutivo per V-JEPA, ampliando ulteriormente le sue capacità di comprensione e interazione con il mondo. L’attuale modello eccelle nella distinzione di azioni dettagliate e interazioni tra oggetti, mostrando promettenti applicazioni future in ambiti come la classificazione delle azioni e il riconoscimento di interazioni complesse.
In conclusione, V-JEPA non è solo un modello di ricerca all’avanguardia, ma anche un esempio lampante del potenziale dell’intelligenza artificiale avanzata. Meta sta guidando il cammino verso un futuro in cui le macchine potranno apprendere e interagire con il mondo in modi sempre più simili agli esseri umani, aprendo nuove strade per la ricerca e applicazioni pratiche nell’intelligenza artificiale.
La pubblicazione di V-JEPA con licenza CC BY-NC, spiega il gruppo di Menlo Park, testimonia l’impegno di Meta nella scienza aperta e responsabile, invitando altri ricercatori a contribuire e estendere questa rivoluzionaria tecnologia. Insomma: è questo solo l’inizio.
Ti potrebbe interessare





16 feb 2024