
Che la virtualizzazione offra diversi benefici è fuori discussione poiché permette di far girare svariati sistemi operativi, anche diversi da quello ospitante, tramite i quali effettuare i propri test. Le usuali modalità, come VirtualBox , sono molto esigenti in termini di risorse perché virtualizzano anche l’hardware sottostante. In questi casi l’applicativo che gira su un sistema host (ospitante) si chiama hypervisor , le cui radici risalgono agli anni ’60 con i primi esperimenti in IBM .
Esistono due tipi di hypervisor che possono girare sulla macchina ospitante: Tipo 2 e Tipo 1 . La differenza sostanzialmente risiede nel fatto che mentre l’hypervisor Tipo 2 necessita di un sistema operativo che lo ospiti e nel quale poter girare (VirtualBox, ad esempio), il Tipo 1 può lanciare direttamente sull’hardware della macchina senza interposizione di un sistema operativo (come VMWare ESXi ).
L’hypervisor è la strada principale per gestire le macchine virtuali in presenza di processori che supportino la replicazione virtuale in hardware: per i processori Intel ci si può imbattere in nomi come VT-x , Intel Virtualization Technology o Virtualization Extensions , mentre per i processori AMD in sigle come AMD/v o Secure Virtual Machine Mode (in alcuni BIOS Asus). Queste voci, a seconda del BIOS, le troviamo in Advanced del menu CPU Configuration oppure in Security . Da osservare che non è una prerogativa assoluta dell’architettura x86, ma è possibile trovarla anche in processori come gli ARM della serie Cortex-A.
Con la presenza di un hypervisor è possibile aggiungere un sistema operativo virtualizzato che permette si di creare quel mix di ambienti di cui si necessita per lavorare allo sviluppo del proprio software, ma in alcune occasioni potrebbe non rivelarsi la soluzione migliore da adottare. Ciò è particolarmente vero quando si necessita di un approccio più modulare atto a migliorare la flessibilità del sistema, così come la manutenibilità e configurabilità.
Contenitori vs hypervisor
L’hypervisor è l’unica strada possibile se si vuole provare/installare un sistema operativo o più semplicemente un applicativo? Certo che no, e per arrivare alle prove illustrate in questo articolo occorrono dapprima un certo numero di considerazioni per comprendere concettualmente l’architettura presente dietro i risultati che vedremo.
In quei casi in cui l’aggiunta di un nuovo sistema operativo (o di un hypervisor) possa essere di troppo, in nostro soccorso arrivano i container (letteralmente “contenitori”) che forniscono un modo per isolare le applicazioni tramite l’uso di un ambiente specifico nel quale possono essere lanciate. Le differenze che contraddistinguono le due tecniche possono essere così riassunte: i contenitori, alla stregua di un hypervisor di Tipo 2, necessitano di un sottostante sistema operativo che fornisca i servizi di base per tutte le applicazioni racchiuse in uno o più container; con un hypervisor si ha un sistema hardware reale (host), hardware virtuali creati dall’hypervisor e molti sistemi operativi installabili.
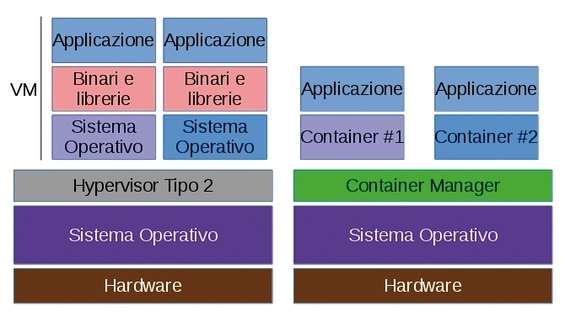
Macchine virtuali con hypervisor a sinistra, contenitori isolati a destra
Per i contenitori, fermo restando il medesimo hardware, non c’è possibilità di hardware virtuali, si ha un solo kernel (che sovraintende tutte le funzioni di accesso alle risorse) e sono possibili tante istanze in user-space . Ciò significa che un hypervisor è caratterizzato da un’alta versatilità ma basse densità, scalabilità e performance, a differenza dei container che possono dar luogo a un’alta densità di applicazioni e un’allocazione dinamica delle risorse con performance (quasi) al livello hardware grazie al basso sovraccarico. Per questo motivo non è raro trovare sistemi che presentano decine (o centinaia) di contenitori in ognuno dei quali vengono lanciate altrettante applicazioni. L’aspetto negativo vede l’accesso alle risorse: poiché i contenitori dipendono dal sottostante sistema operativo allora alcuni servizi come l’accesso al file system, alla rete, alla RAM potrebbero essere limitati a seconda delle impostazioni. Comunque, niente e nessuno vieta di avere, a seconda delle necessità, entrambe le soluzioni sullo stesso sistema, prendendo il meglio da ciascuna di esse.
Il concetto Namespaces
Ogni volta che avviamo la nostra distribuzione viene lanciato, dopo il caricamento del kernel in memoria, un processo caratterizzato dall’avere il PID (Process IDentifier) di valore pari a 1. È il padre di tutto l’albero dei processi attivi durante l’uso del sistema operativo: il suo compito è gestire il corretto avvio dei demoni e dei servizi correlati attraverso l’avvio di numerosi altri processi, ognuno dei quali avrà PID maggiore di 1. Questa caratteristica permette di classificare i processi in una gerarchia ad albero basata sulla relazione padre-figlio. Possiamo evidenziare in una modalità pseudo-grafica l’albero genealogico dei processi presenti nel sistema previo uso del comando pstree -A ( man pstree ). Nei sistemi GNU/Linux un processo può essere creato attraverso le chiamate di sistema fork() o clone() , per approfondimenti digitare rispettivamente man 2 fork e man 2 clone . A partire dal kernel 2.4.19 (Agosto 2002) fece la comparsa la flag CLONE_NEWNS con il significato di new namespace e per la quale era, ed è, richiesta la capability CAP_SYS_ADMIN ( man 7 capabilities ). Non erano pianificate altre flag che lasciassero intendere quello che poi si è succeduto negli anni con nuovi rilasci del kernel: era l’inizio dei namespaces nel kernel Linux. Ma cosa sono esattamente? Chiunque abbia un po’ di familiarità con un ambiente chroot , può già avere una basilare idea delle capacità del kernel e di che cosa sia possibile realizzare con i namespaces. Infatti, esattamente come chroot fa vedere ai processi una data directory come la radice del file system, analogamente i Linux namespaces permettono ad alcune proprietà del sistema di essere modificate in maniera indipendente. All’atto pratico si traduce nella capacità dei processi di poter creare un albero dei processi “innestato”, laddove ogni ramo che origina una nuova ramificazione può caratterizzarsi dall’avere un insieme totalmente isolato di processi.
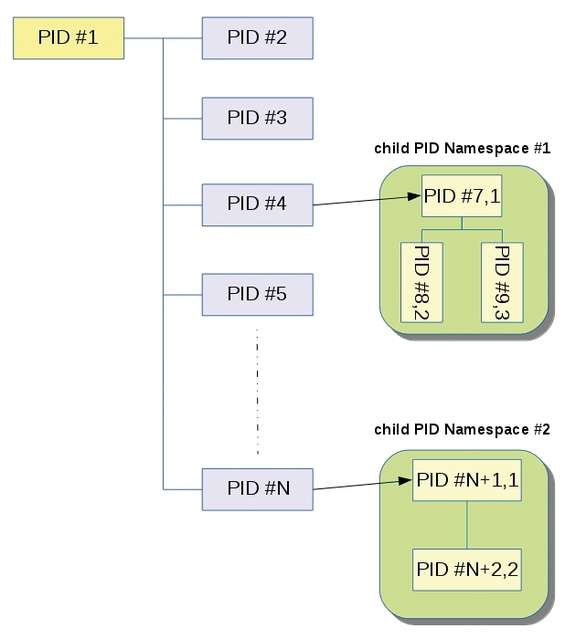
Rappresentazione di principio dei child namespaces
Nella figura sopra riportata possiamo osservare come un processo, sfruttando la funzione del PID Namespaces , può originare un namespaces figlio ( child ), ovvero un nuovo albero il cui primo processo presenta PID 1 e diventerà il processo radice nel nuovo child namespaces . Ma c’è di più, la funzione namespaces isolation permette ai processi di essere isolati rispetto ad altri processi sullo stesso sistema, determinando così una gestione separata della tabella dei processi; a differenza di un ambiente chroot dove la gestione dei processi risulta condivisa.
A questo punto il figlio può reiterare la procedura generando così un nuovo PID Namespaces e così a seguire. Si potranno intuire le capacità applicative di una siffatta caratteristica. Ad esempio, è possibile eseguire in una modalità sicura un programma sotto test o addirittura sconosciuto sul sistema server senza che questo lo possa pregiudicare. Strumenti come namespaces sono alla base dei fornitori di servizi PaaS (Platform as a Service) ovvero completi ambienti di sviluppo e distribuzione presenti nel cloud computing e dove vengono assegnate le risorse in funzione delle necessità del cliente. Senza entrare nel dettaglio, poiché fuori dalla portata del presente articolo, diciamo solo che l’architettura dei namespaces consta di 3 chiamate di sistema per l’implementazione: clone() , crea un nuovo processo e un nuovo namespaces con il primo collegato al secondo; unshare() , non crea un nuovo processo ma un nuovo namespace e collega ad esso il processo; setns() , per l’associazione a un esistente namespaces.
In definitiva, i namespaces sono utili per creare processi che sono più isolati dal resto del sistema senza necessità alcuna di usare una virtualizzazione hardware a basso livello.
Gruppi di controllo
Altra caratteristica introdotta a partire dalla versione 2.6.24 del kernel sono i CGroups (Control Groups), ovvero la possibilità di suddividere in gruppi i processi in esecuzione. Ma a che scopo? Poter controllare al meglio l’allocazione delle risorse assegnate a ogni singolo gruppo di processi. Per risorse intendiamo le usuali quali tempo e numero di CPU, RAM, larghezza di banda per i processi che usano la rete e le risorse di I/O (disco e periferiche). Le applicazioni associabili a CGroups possono spaziare dal “semplice” programma sotto test fino alla creazione di un intero sistema operativo all’interno di un ambiente controllato (contenitore), analogamente a ciò che si potrebbe fare con una virtualizzazione utilizzando un hypervisor, ma senza necessità alcuna di replicare un intero hardware. Pro e contro di questa soluzione possono essere diversi a seconda dell’obiettivo che ci si prefigge. Il più grande vantaggio è il basso impatto sulla macchina ospitante e, per contro, qualora si volesse lanciare un sistema ospite, è possibile solo per sistemi GNU/Linux poiché la funzionalità si appoggia al kernel della macchina ospitante. Eviteremo di perderci in dettagli implementativi, anche perché saranno effettuati in maniera trasparente all’utente dal programma che si andrà a utilizzare. Ad ogni modo, un principio di funzionamento è dovuto al fine di comprenderne la dinamica. Ipotizziamo di avere due utenti o comunque diversi programmi appartenenti a due gruppi differenti e di pianificare per essi l’assegnazione delle risorse.
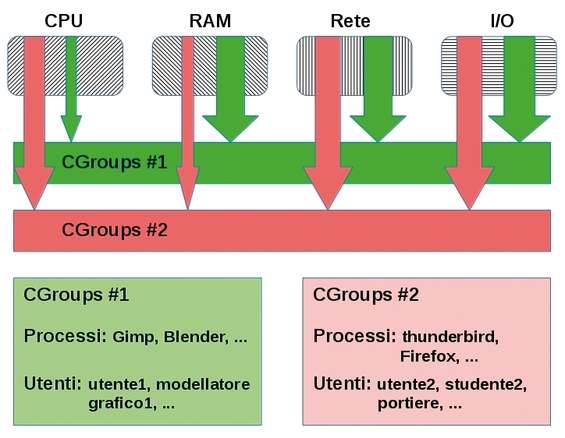
Schema di principio dei gruppi di controllo
A fronte delle 4 risorse principali dobbiamo decidere quante assegnarne al primo utente (o al primo gruppo di programmi) e quante al secondo.
Qualsiasi cosa i processi/programmi/utenti appartenenti ai gruppi vogliano lanciare potranno avere un limite sulle risorse. Ad esempio, i processi del gruppo 1 potranno sfruttare solo una percentuale del tempo di CPU più bassa di quella sfruttabile dai processi del gruppo 2. Di contro viene assegnato un quantitativo di RAM minore per l’ambiente del gruppo 2 rispetto all’ambiente controllato del gruppo 1. Analoghe considerazioni per la larghezza di banda e l’I/O.
Ma diverse possono essere le condizioni: ad esempio, un programma di calcolo matriciale a cui occorre buona parte della potenza di calcolo della CPU e la RAM per i dati temporanei isolandolo per ciò che ne attiene la rete e l’I/O, a meno che il programma stesso utilizzi file temporanei su disco. La rimanente parte di CPU e memoria la si può assegnare a un gruppo di lavoro, ad esempio un gruppo di utenti che utilizzano solo programmi per ufficio e la posta elettronica: in questo caso occorre prevedere una quota di I/O e di larghezza di banda. Quanto riportato sono solo delle possibili situazioni di gruppi di processi e/o di lavoro associati a utenti diversi: GNU/Linux è pur sempre un sistema multiutente. Le opzioni utilizzabili all’interno dei file di configurazione per l’assegnazione delle risorse sono innumerevoli. Ad esempio memory.usage_in_bytes riporta l’uso corrente della memoria usata dai processi nei gruppi, oppure cpuset.cpus specifica le CPU a cui i processi del gruppo gli è permesso accedere. Questi valori vanno inseriti nel file /etc/cgconfig.conf dopo averlo opportunamente generato utilizzando ad esempio l’utility cgsnapshot . Argomenti, comunque, che esulano dall’attuale contesto. Coloro che fossero interessati ad approfondire i CGroups possono leggere la documentazione allegata al kernel in /usr/src/
In definitiva, Namespaces e CGroups sono due delle principali tecnologie presenti nel kernel Linux da utilizzare per creare ambienti controllati . Per riassumere e semplificare: mentre la funzione CGroups offre un modo per raggruppare un insieme di processi e confinarli in un ambiente che controlla le risorse, la funzione Namespaces limita ai processi, o ad un loro gruppo, la visibilità al sistema isolandoli così da altri processi (o gruppi) sullo stesso sistema sottostante.
L’avvio delle distribuzioni
Ricordate il processo con PID uguale a 1? È giunto il momento di capire di cos’è. Trattasi di un demone per la gestione dei servizi del sistema sviluppato appositamente per sostituire lo storico init . Stiamo parlando di Systemd , un programma/servizio/demone master che gestisce l’avvio e il controllo di altri demoni. Ad esclusione di Gentoo e Slackware, praticamente tutte le maggiori distribuzioni sono passate ad adottarlo: iniziò Fedora 15 nel 2011. A seguire OpenSUSE, Mageia e di recente Debian. Se diamo un’occhiata al file /sbin/init ci accorgeremo che altro non è che un link al binario systemd nel percorso /usr/lib/systemd/ . Poiché systemd provvede al caricamento di tutti i servizi nonché alla loro supervisione (attivazione o disattivazione) è possibile associarlo come il padre di tutti i servizi. Presenta molte funzioni native di utilità per gli amministratori così come per gli utenti desktop. Ad esempio systemd-analyze mostra i tempi di caricamento per il kernel, i servizi e per l’account utente; tempi che possono essere particolareggiati utilizzando systemd-analyze plot > Avvio.svg : verrà creato un file SVG nella cartella dove è stato lanciato il comando, che potrà essere aperto con un browser per valutare le tempistiche di ogni singolo servizio lanciato durante la fase di boot, con tanto di legenda e grafici. Altra peculiarità di systemd è la riduzione dei tempi di avvio, grazie a una logica di controllo sui servizi e alla parallelizzazione delle attivazioni senza inutili attese.
Systemd e il suo container
Ma perché parlare di questo nuovo sistema di avvio? E come rientra nel discorso dei container Linux? La motivazione è che systemd può sfruttare la possibilità dei raggruppamenti dei processi offerti dal kernel se l’opzione CONFIG_CGROUPS è abilitata. In genere lo è di default e possiamo verificarlo con cat /boot/config-$(uname -r) | grep CONFIG_CGROUPS che ci restituirà CONFIG_CGROUPS=y . Possiamo già vedere l’organizzazione in gruppi di controllo di systemd impartendo il comando systemd-cgls .
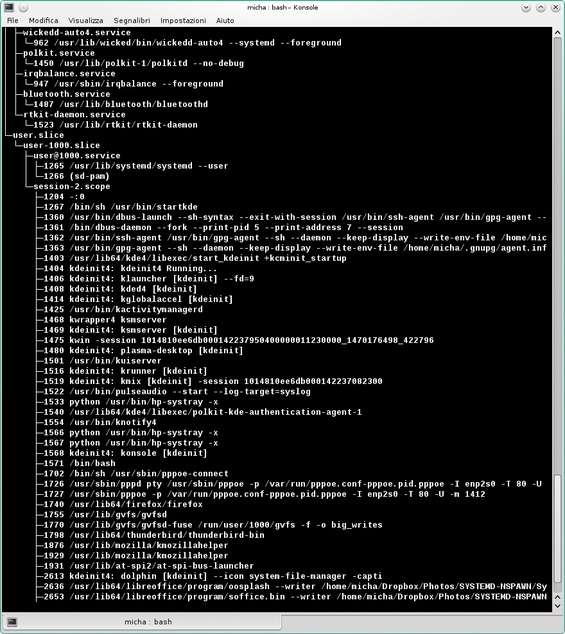
Gerarchia dei gruppi di controllo in systemd
Oltre alle funzioni fin qui riportate a systemd è associato un binario di nome systemd-nspawn . Dalle prime righe del manuale ( man systemd-nspawn ) si legge: “systemd-nspawn genera un namespaces container adatto per il debug, il test e la costruzione di ambienti (…) può essere utilizzato per lanciare un comando o un sistema operativo in un leggero namespaces container. Per certi versi è simile a chroot ma più potente poiché permette una completa virtualizzazione della gerarchia del filesystem (…)”.
Una prima applicazione
Prima di tutto systemd-nspawn richiede che il sistema operativo nel container presenti systemd avviato con PID 1. Questo vuol dire che le distribuzioni che non ne fanno uso (ad esempio Slackware e Ubuntu prima della versione 15.04) non funzioneranno; per lanciarle occorrerà fare un lavoro extra per installare systemd. Non solo, al fine di evitare di utilizzare un albero non Linux, systemd andrà alla ricerca del file os-release in /usr/lib/ o /etc/ .
Fatta questa premessa, possiamo usare systemd-nspawn per fare un test con Fedora 24. Inseriamo il DVD della distro e spostiamoci nella cartella LiveOS : troveremo il file squashfs.img che contiene tutto l’albero della distribuzione.
Creiamo 3 directory. Le prime due nella home utente: nella prima monteremo lo squashfs, nella seconda il contenuto dello squashfs ( mkdir squashfs , mkdir root_Fedora ). La terza, che può essere un’altra partizione o altro disco, ad esempio /mnt/test/Fedora24 , la useremo come container da attivare e lanciare con systemd-nspawn. Effettuiamo il montaggio dello squash file system nella prima directory con mount /punto/montaggio/DVD/Fedora-WS-Live-24-1-2/LiveOS/squashfs.img squashfs/ .
Entrando in squashfs dovremmo trovare una cartella di nome LiveOS e all’interno il file rootfs.img . Eseguiamo il montaggio di tale file con mount squashfs/LiveOS/rootfs.img root_Fedora/ .
Di nuovo, entrando ora nella cartella root_Fedora vedremo l’intero albero del file system. Copiamone il contenuto sul file system locale con rsync -av root_Fedora/ /mnt/test/Fedora24/
Al termine dell’operazione di copia (occorrerà qualche minuto poiché la dimensione si aggira sui 4,3 GB) smontiamo, ad eccezione di “/mnt/test/Fedora24/”, le directory con umount nome_directory/ e rimuoviamole ( rm -R nome_directory ). Ora non resta che lanciare la distribuzione con systemd-nspawn -D /mnt/test/Fedora24 -b .
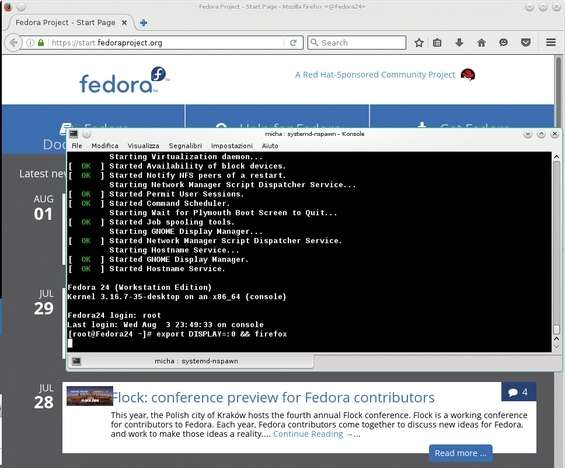
Firefox lanciato da un container con Fedora 24 in una OpenSUSE 13.2
Come mostrato in figura, sebbene Fedora 24 utilizzi un kernel della versione 4.x un uname -r evidenzia un kernel 3.16.7. Perché? Il motivo è semplice ed è stato già accennato in precedenza: il contenitore si appoggia al kernel della macchina ospitante, per questo motivo non si possono installare sistemi operativi differenti da GNU/Linux. Dal container proviamo ad avviare un programma grafico, ad esempio Mozilla Firefox, con il comando export DISPLAY=:0 && firefox . Dopo qualche secondo vedremo una sessione di Firefox aprirsi. Se non crediamo che sia all’interno del container possiamo sempre lanciare il comando systemd-cgls e vedere a quale gruppo appartiene questa sessione di Firefox: verrà mostrato l’utente e il container Fedora 24. A questo punto è possibile valutare diverse caratteristiche del container utilizzando specifici comandi.
Uno dei primi comandi da utilizzare, una volta creato e lanciato il contenitore, potrebbe essere machinectl : senza argomenti elenca i container in esecuzione ed è equivalente all’uso dell’opzione list . Nell’output, alla colonna MACHINE è evidenziato il nome, o i nomi qualora fossero più di uno, del container in esecuzione. Il comando machinectl status nome_container mostra dettagliate informazioni sul container in esecuzione. Con systemd-cgtop possiamo leggere le risorse utilizzate. Infine si può pensare di utilizzare systemd-analyze -M nome_container per conoscerne il tempo di avvio.
Debian Sid e Apache
Vediamo ora come installare una versione minimale di Debian seguita dall’installazione, e successivo lancio, del Web server Apache. Creiamo una directory Debian in una partizione o su un secondo disco, anche esterno (ad esempio mkdir /mnt/test/Debian ). Assicuriamoci che sulla distribuzione in uso (la macchina host) sia installato il programma debootsrap il quale è presente nei repository di molte distribuzioni. Da utente amministratore, ipotizzando di voler costruire un sistema i386, diamo il comando debootstrap –arch=i386 –no-check-gpg testing /mnt/test/Debian/ .
Le operazioni dureranno qualche minuto terminate le quali si ha un sistema Debian testing di base pronto per essere lanciato. Iniziamo a impostare la password dell’utente root con systemd-nspawn -D /mnt/Portatile/Debian/ passwd : dopo aver premuto Invio inseriamo la password, premiamo Invio e inseriamola nuovamente. Aggiungiamo un utente al container con systemd-nspawn -D /mnt/Portatile/Debian/ useradd nome_utente quindi aggiorniamone i repository systemd-nspawn -D /mnt/Portatile/Debian/ apt-get update . Avviamo il container ( systemd-nspawn -bD /mnt/Portatile/Debian/ ), effettuiamo il login con l’utente root inserendo la password, installiamo il Web server con apt-get install apache2 e procediamo al suo avvio con systemctl start apache2 .
A questo punto scarichiamo il browser testuale Lynx con wget http://ftp.de.debian.org/debian/pool/main/l/lynx/lynx_2.8.9dev9-1_i386.deb e installiamolo con apt-get install -f /root/lynx_2.8.9dev9-1_i386.deb (ricordiamo che di default siamo nella cartella /root dell’utente amministratore). A questo punto lanciamo il browser con lynx http://localhost per vedere la classica schermata di Apache “It works!” e la tipica personalizzazione di Debian.
Spegniamo il container e proviamo ad attivare la rete affinché la medesima schermata sia visibile anche dal browser grafico della macchina host. Riavviamo il container con il comando systemd-nspawn -b -D /mnt/test/Debian/ –network-veth ed effettuiamo il login. Con la nuova opzione riportata nel container apparirà una nuova interfaccia di rete di nome host0 . Se non siamo sicuri (ri)avviamo i servizi di rete di Debian ( systemctl restart systemd-networkd.service systemd-resolved.service ).
Ora, se nel sistema host da un terminale diamo il comando ip link show troveremo una nuova interfaccia di nome ve-Debian , quella del container, in stato DOWN . Configuriamo la rete lato host con ifconfig ve-Debian 192.168.2.1 netmask 255.255.255.0 broadcast 192.168.2.255 e verifichiamo che sia stata attivata elencando le interfacce con ifconfig . Passiamo al sistema guest (il container) nel quale daremo il comando ifconfig host0 192.168.2.2 netmask 255.255.255.0 broadcast 192.168.2.255 . Assicurandoci, al solito, che sia presente nell’elenco delle interfacce attive.
A questo punto verifichiamo la raggiungibilità delle due interfacce: dal sistema guest proviamo a pingare l’interfaccia host con ping 192.168.2.1 e analogamente dall’interfaccia host verifichiamo la raggiungibilità dell’interfaccia guest con ping 192.168.2.2 . Se c’è risposta dall’una e dall’altra allora dal sistema host lanciamo Firefox e colleghiamoci al guest riportando nella barra degli indirizzi 192.168.2.2 . Il risultato è visibile nell’immagine seguente.
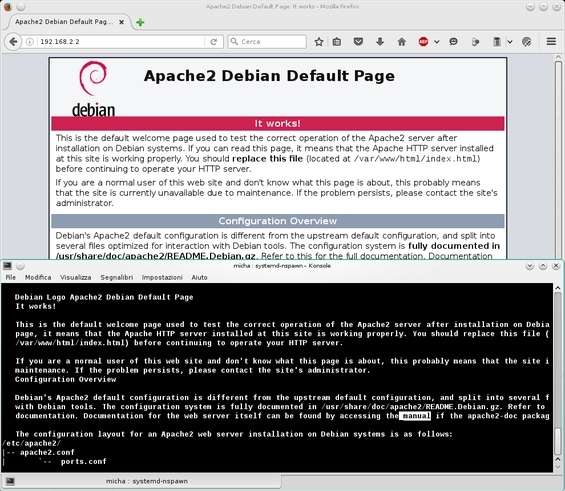
Primo piano Lynx nel container Debian, sullo sfondo Firefox in OpensSUSE 13.2
Ciò che è stato creato, quindi, è la gerarchia visibile in quest’ultima immagine.
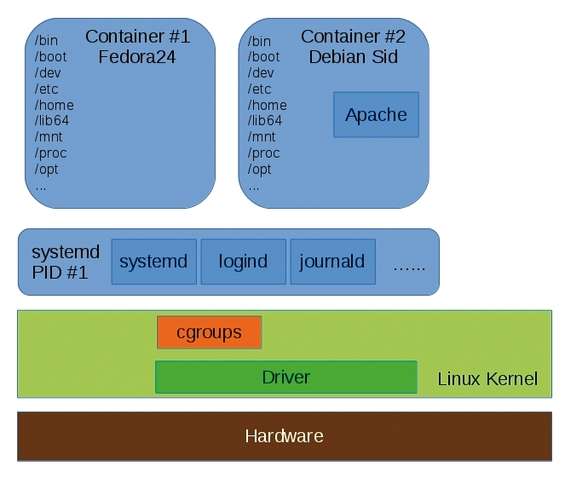
Le procedure riportate hanno creato due container: Fedora24 e Debian
Ti potrebbe interessare


30 set 2016