

Le unità di elaborazione grafica, o GPU (Graphics Processing Unit), hanno superato da tempo il loro ruolo tradizionale relegato al solo rendering grafico per videogiochi e applicazioni 3D. Oggi rappresentano delle componenti fondamentali nell’elaborazione di grandi quantità di dati, soprattutto nel campo dell’Intelligenza Artificiale (AI) e del Machine Learning (ML). Grandi colossi dell’IT come OpenAI, Google e Meta, hanno investito somme ingenti in GPU per alimentare i propri Data Center. Non è quindi un caso se negli ultimi anni Nvidia è cresciuta ad un ritmo talmente in termini di valore da diventare l’azienda più capitalizzata al mondo.
Non sono però soltanto le grandi aziende a riconoscere il ruolo dei processori grafici per le applicazioni di AI. Anche le startup e in generale le imprese di medie e piccole dimensioni stanno comprendendo l’importanza di integrare risorse GPU nei loro processi di business.
Il problema: penuria delle GPU e costi delle risorse
Si stima che nei prossimi anni l’uso dei Data Center aumenterà di circa sei volte rispetto all’attuale richiesta di risorse computazionali. Questo incremento è trainato dalla diffusione di tecnologie, come appunto AI, ML e analisi dei Big Data, che richiedono una potenza di calcolo sempre maggiore. Le GPU, con la loro capacità di eseguire calcoli paralleli ad alta velocità, sono diventate quindi essenziali per gestire questi workload.
L’incremento della domanda ha portato a una penuria di GPU sul mercato, con conseguenti aumenti dei prezzi e difficoltà nel reperimento dei componenti. Le aziende si trovano quindi a dover affrontare sfide non sempre facili da superare per soddisfare le proprie esigenze computazionali senza compromettere la sostenibilità economica dei progetti. Una soluzione è data dalla possibilità di accedere a risorse remote, come nel caso del servizio Serverless GPU di Seeweb.

La soluzione: Serverless GPU di Seeweb
Serverless GPU è un modello di computing che combina i vantaggi del computing serverless con la potenza delle GPU. In un ambiente serverless, le risorse vengono allocate automaticamente in risposta alle richieste delle applicazioni, senza che l’utente debba preoccuparsi della gestione dei server o della complessità dell’infrastruttura. Applicato alle GPU, questo significa che le risorse sono disponibili quando necessarie, in modalità on-demand, senza la necessità di investimenti in hardware dedicato come accade quando si è vincolati alle configurazioni on-premise.
Questo approccio offre numerosi vantaggi. La scalabilità automatica permette alle risorse GPU di essere allocate e scalate in base alle esigenze dell’applicazione, garantendo prestazioni ottimali anche in presenza di picchi di lavoro. Inoltre, grazie al modello pay-per-use, le aziende pagano solo per l’effettivo utilizzo delle GPU, riducendo significativamente i costi operativi rispetto ad un’infrastruttura implementata localmente.
La gestione semplificata è un altro aspetto centrale. Un provider Cloud come Seeweb si occupa della manutenzione e dell’aggiornamento dell’hardware. Liberando le aziende da queste responsabilità e consentendo loro di concentrarsi sullo sviluppo dei propri progetti. La flessibilità delle risorse permette poi di adattarsi rapidamente alle dinamiche di mercato.
Seeweb offre un servizio Cloud native Serverless GPU che integra perfettamente le GPU nell’ecosistema di Kubernetes, standard de facto per l’orchestrazione dei container. Questa integrazione permette di sviluppare e distribuire applicazioni AI e ML in pochi minuti, grazie al provisioning delle GPU in Cloud. Gli utenti possono gestire task di inferenza e training con la massima efficienza, come se operassero su un cluster locale, sfruttando la potenza dei processori grafici. Inoltre, la compatibilità completa con qualsiasi ambiente Kubernetes è garantita dalla conformità all’implementazione Virtual Kubelet di Microsoft.
Perché Seeweb ha scelto Kubernetes
Per utilizzare il servizio Serverless GPU di Seeweb è necessario disporre di un ambiente Kubernetes preconfigurato. L’installazione dell’agente open source k8sGPU permette di creare un nodo virtuale nel cluster Kubernetes esistente che funge da ponte verso le GPU in Cloud. In questo modo, si possono schedulare i pod per i progetti di AI e Deep Learning come su qualsiasi altro worker node. k8sGPU gestisce l’allocazione delle GPU in modo dinamico, senza dover apportare modifiche rilevanti all’infrastruttura esistente.
Una volta attivato il nodo virtuale è possibile iniziare a utilizzare le GPU in Cloud in tempi rapidi. Schedulando i pod che richiedono le risorse GPU e gestendo la loro allocazione in modo efficiente.
Kubernetes è una piattaforma libera e aperta che automatizza il deployment, la scalabilità e la gestione delle applicazioni containerizzate. Utilizzandola, aziende e sviluppatori possono orchestrare facilmente i container su larga scala, ottimizzare la gestione delle risorse e garantire l’affidabilità e la disponibilità delle applicazioni. L’integrazione delle risorse GPU in Kubernetes consente di sfruttare appieno queste funzionalità anche per applicazioni che richiedono elevata capacità di calcolo.
I piani Serverless GPU di Seeweb
Seeweb offre piani differenti per soddisfare esigenze diverse. A ciascun piano corrisponde l’istanza di una GPU specifica, ad esempio NVIDIA L4 per quello più economico, adatta per applicazioni di inferenza e rendering, fino alle potenti A100 e H100 per applicazioni di AI ad altissime prestazioni. Le configurazioni permettono di scegliere il numero di GPU (da 1 a 8 per ciascun piano tranne che per quello basato su H100) e la quantità di GPU RAM (da 24 a 320 GB) varia da piano a piano. I provisioning serverless GPU possono essere configurati e utilizzati anche per brevi periodi, a partire da un’ora.
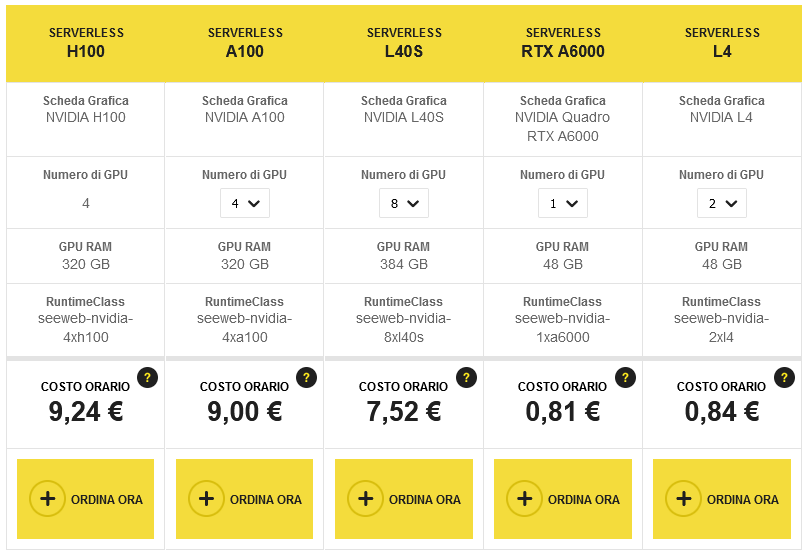
È importante sottolineare che le risorse GPU sono totalmente dedicate, questo vuol dire che sono disponibili ogni volta che se ne presenta la necessità. I il provisioning multi-GPU avviene molto rapidamente, in appena qualche secondo, è così fornita la più alta capacità di calcolo per i carichi di lavoro generati dalle applicazioni basate sull’Intelligenza Artificiale e i modelli generativi.
Tutti i piani del servizio Serverless GPU di Seeweb offrono connettività pari a 10 Gbps, assistenza tecnica 24x7x365 da parte di professionisti competenti e un uptime garantito da SLA (Service Level Agreement) fino al 99.9% con cui avvalersi di continuità di servizio e performance elevate in qualsiasi condizione.
Sono supportati la maggior parte dei servizi Managed Kubernetes pubblici come AKS, EKS e GKE, le configurazioni on premise basate su Vanilla Kubernetes e piattaforme incentrate sulla gestione dei container come OpenShift, Tanzu Kubernetes e Rancher.
La fatturazione del servizio si basa su un modello a consumo di tipo pay-per-use su base oraria. Potendo richiedere le risorse GPU on-demand l’utilizzatore paga soltanto per le risorse effettivamente utilizzate che sono scalabili senza limiti o eliminabili in base alle necessità. Vengono inoltre forniti dei report periodici sull’impiego delle GPU per monitorare costantemente l’entità delle spese, senza costi nascosti, fin dalla prima attivazione.
Conclusioni
Implementare e addestrare modelli di Intelligenza Artificiale richiede grandi capacità di calcolo, così come lo sviluppo di applicazioni basate sulla AI. Questo espone le aziende a costi che possono rivelarsi imprevedibili e, nei casi peggiori, difficilmente sostenibili.
Per questa ragione Seeweb ha creato il servizio Serverless GPU che consente di accedere alle risorse GPU in modalità on-demand. L’utilizzatore può quindi scalare la potenza computazionale in base alle esigenze del proprio progetto, con la sicurezza offerta dal modello di tariffazione pay-per-use che permette di pagare solo per ciò che si consuma. Con Serverless GPU, pensato per la completa integrazione con Kubernetes, le risorse GPU potranno essere utilizzate come se fossero disponibili in un cluster locale.
Ti potrebbe interessare





10 gen 2025