
Nvidia si prepara a dare battaglia all’ultima generazione di processori grafici di AMD, gli ATI Radeon serie 5800 , con quella che definisce “la più avanzata architettura di GPU computing mai realizzata”. Il suo nome in codice è Fermi , in onore del celebre scienziato italiano , e verrà utilizzata da Nvidia nella sua imminente linea di GPU GeForce GT300 a 40 nanometri : questa rimpiazzerà gli attuali chip GT200 che si trovano alla base di tutte le schede video GeForce GTX 2xx.
 Fermi è la prima architettura di Nvidia ad essere stata concepita fin dall’inizio per l’utilizzo in soluzioni di high performance computing (HPC). Pur non adottando un’architettura simil-x86 come la futura GPU Larrabee di Intel, Fermi è molto più simile ad una CPU di qualunque altra architettura grafica oggi sul mercato.
Fermi è la prima architettura di Nvidia ad essere stata concepita fin dall’inizio per l’utilizzo in soluzioni di high performance computing (HPC). Pur non adottando un’architettura simil-x86 come la futura GPU Larrabee di Intel, Fermi è molto più simile ad una CPU di qualunque altra architettura grafica oggi sul mercato.
La nuova tecnologia di Nvidia aspira a essere l’espressione più avanzata del cosiddetto GPGPU (General Purpose computation using GPU), un modello di computing che utilizza i processori grafici per compiti general purpose, come l’esecuzione di applicazioni che non prevedono il rendering di immagini 3D. Tale possibilità è data dalla programmabilità delle schede grafiche più recenti, che va sotto il nome di shader model .
“Invece di una GPU adattata al supercomputing, ci siamo assunti il rischio di lanciare una nuova architettura progettata soprattutto per essere un computer e per trattare grafica ed elaborazione parallela come pari cittadini” ha spiegato Jen-Hsun Huang, CEO di Nvidia, durante la presentazione di Fermi presso la GPU Technology Conference di San Josè. “La nostra nuova architettura è lo spirito di un supercomputer nel corpo di una GPU”.
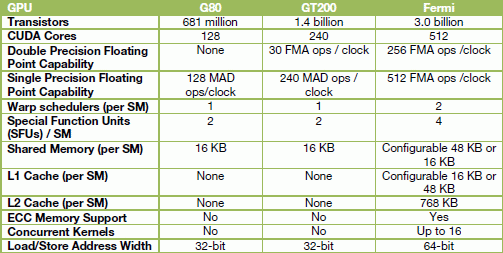
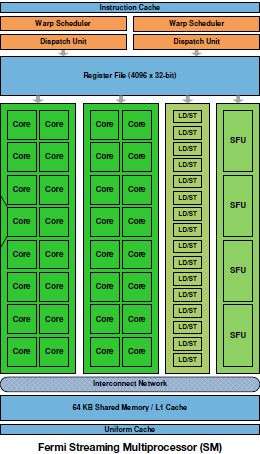
Un corpo, quello dei futuri processori GT300, che conterrà ben 3 miliardi di transistor e 512 unità di elaborazione , chiamate CUDA Core . Per comprendere che “bestia” sia Fermi, basti ricordare che il neonato processore eight-core Nehalem-EX di Intel integra “solo” 2,3 miliardi di transistor, e che l’altrettanto recente GPU Radeon 5870 di AMD ne include 2,15 miliardi. Vale poi la pena notare come il numero dei core di elaborazione sia più che raddoppiato rispetto a quello delle GPU GT2xx, che ne contenevano 240.
Fermi è la prima architettura di Nvidia a supportare la tecnologia DirectX 11 e la specifica Shader Model 5.0, nonché la prima ad introdurre il supporto alle memorie GDDR5 , alle quali è stato dedicato un bus a 384 bit (contro i 256 bit delle attuali ATI Radeon top di gamma). Fermi adotta poi un sistema di cache gerarchico su due livelli , costituito da 1 MB di cache L1 e 784 KB di cache L2 unificata, e il nuovo motore GigaThread , che permette l’esecuzione di più kernel di uno stesso contesto applicativo massimizzando il parallelismo.
 Per la prima volta in un’architettura grafica è inoltre presente il supporto alle memorie ECC (Error Correction Code), caratteristica pensata espressamente per l’utilizzo in ambito server, e all’esecuzione nativa di codice C++ e Fortan . Ai cluster di server è altresì dedicato il supporto al formato dei numeri in virgola mobile Half Speed IEEE 754 Double Precision . A tale proposito, Nvidia afferma che la sua futura generazione di GPU fornirà, nei calcoli in virgola mobile a doppia precisione, performance fino ad otto volte superiori rispetto alle GT2xx : ciò le rende particolarmente adatte per le applicazioni scientifiche, finanziarie e ingegneristiche.
Per la prima volta in un’architettura grafica è inoltre presente il supporto alle memorie ECC (Error Correction Code), caratteristica pensata espressamente per l’utilizzo in ambito server, e all’esecuzione nativa di codice C++ e Fortan . Ai cluster di server è altresì dedicato il supporto al formato dei numeri in virgola mobile Half Speed IEEE 754 Double Precision . A tale proposito, Nvidia afferma che la sua futura generazione di GPU fornirà, nei calcoli in virgola mobile a doppia precisione, performance fino ad otto volte superiori rispetto alle GT2xx : ciò le rende particolarmente adatte per le applicazioni scientifiche, finanziarie e ingegneristiche.
L’architettura Fermi verrà utilizzata per tutte le prossime schede grafiche GeForce, Quadro e Tesla, rispettivamente dedicate al settore desktop, workstation e HPC.
Un prototipo di scheda Tesla basata su Fermi è stato mostrato da Huang presso la GPU Technology Conference. Schede come questa verranno utilizzate dall’Oak Ridge National Laboratory ( ORNL ) per costruire un supercomputer dedicato alla simulazione dei cambiamenti climatici. Attualmente ORNL utilizza il famoso supercomputer Jaguar di Cray, basato su processori Opteron, secondo al mondo per potenza di calcolo dietro al Roadrunner di IBM.
“Con l’aiuto della tecnologia di Nvidia, Oak Ridge è intenzionata a creare una piattaforma di computing che, entro 10 anni, sia in grado di fornire una potenza di calcolo nell’ordine degli exaFLOPS (miliardi di miliardi di operazioni matematiche in virgola mobile al secondo, NdR)”, ha dichiarato Jeff Nichols, associate lab director di Oak Ridge per il Computing and Computational Sciences.
Oak Ridge darà altresì vita a un consorzio per lo sviluppo di nuove piattaforme di calcolo ibride, costituite da CPU, GPU ed eventuali unità di calcolo specializzate.
 Per mettere mano su una scheda grafica basata su Fermi i consumatori dovranno invece attendere l’inizio del prossimo anno. Sebbene Nvidia non abbia ancora rivelato i prezzi delle sue future GPU, gli esperti si attendono che inizialmente saranno piuttosto costose : ad influire sul prezzo ci sarà la generosa dimensione del die, stimata tra i 450 e i 500 mmq, l’interfaccia di memoria a 384 bit e la relativamente nuova tecnologia di processo a 40 nm.
Per mettere mano su una scheda grafica basata su Fermi i consumatori dovranno invece attendere l’inizio del prossimo anno. Sebbene Nvidia non abbia ancora rivelato i prezzi delle sue future GPU, gli esperti si attendono che inizialmente saranno piuttosto costose : ad influire sul prezzo ci sarà la generosa dimensione del die, stimata tra i 450 e i 500 mmq, l’interfaccia di memoria a 384 bit e la relativamente nuova tecnologia di processo a 40 nm.
Per un approfondimento tecnico sull’architettura Fermi è possibile leggere questo documento , in PDF, pubblicato da Nvidia.
Insieme alla sua nuova architettura, Nvidia introdurrà anche un ambiente di sviluppo, chiamato Nexus , specificamente pensato per lo sviluppo di applicazioni GPGPU in C (CUDA), OpenCL e DirectCompute. L’IDE di Nexus potrà integrarsi a Visual Studio, e consentire così il debugging e l’analisi del codice sorgente per le GPU utilizzando gli stessi strumenti con cui gli sviluppatori scrivono abitualmente codice x86 per Windows.
Di seguito un video in cui viene mostrato Nexus in azione.
Alessandro Del Rosso
Ti potrebbe interessare


1 ott 2009