
Alcuni ricercatori del Laboratorio di Scienze Informatiche e Intelligenza Artificiale (CSAIL) del MIT, hanno sviluppato un sistema in grado di trasferire un blocco di codice appartenente ad un certo software all’interno di un altro , integrandolo con esso: hanno realizzato quindi, un primo caso d’uso di uno scenario che finora è stato appannaggio quasi esclusivo dell’intervento umano: il riutilizzo del codice .
Il sistema, chiamato CodeCarbonCopy (CCC) , richiede ancora alcuni interventi manuali : uno sviluppatore deve identificare sia il codice relativo alla funzionalità da trasferire all’interno del secondo programma, sia il punto esatto – all’interno del codice del secondo programma – in cui il trasferimento deve avvenire.
Una volta definiti questi parametri, CodeCarbonCopy esegue sia il codice di partenza che quello di destinazione, passando in input lo stesso file: durante queste esecuzioni, vengono salvate delle espressioni simboliche atte a rappresentare ogni valore computato dal codice; queste espressioni andranno a formare un mapping tra la rappresentazione del dato usata all’interno del codice sorgente e quella usata nel programma di destinazione.
Per fare ciò, i ricercatori hanno realizzato un algoritmo di strumentazione, scritto in un linguaggio da loro ideato – chiamato semplicemente “Core” – rappresentato attraverso il software Valgrind.

Nello specifico, l’algoritmo di strumentazione è in grado di identificare e salvare il risultato di ogni singola operazione: assegnazioni, accesso a puntatori a memoria, operatori binari (identificati dal simbolo ⊕), variabili puntate, allocazioni dinamiche, letture da file.
In seguito, il mapping viene utilizzato per generare dei data adapter di input e di output: il primo legge le strutture dati del programma di destinazione per popolare quelle del codice sorgente, che il codice trasferito andrà ad accedere; il secondo scrive i valori computati dal codice sorgente all’interno delle strutture dati del programma di destinazione. In poche parole, gli adapter consentono al codice sorgente di funzionare con le proprie strutture dati, provvedendo alle opportune operazioni di conversione dei parametri di input e di output , per garantire la compatibilità con il programma di destinazione.
Infine, dopo aver eliminato parti irrilevanti del codice sorgente, attraverso una procedura di analisi statica, il codice viene trasferito all’interno del programma di destinazione. Durante quest’ultima fase, eventuali variabili globali utilizzate dal codice di partenza vengono rimpiazzate con degli analoghi puntatori, al fine di facilitare l’operazione.
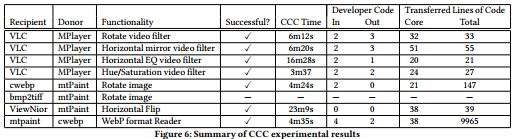
I ricercatori hanno allegato anche una serie di otto test di sperimentazione, in ognuno dei quali alcune funzionalità sono state trasferite da un programma all’altro: nello specifico, sono stati utilizzati programmi di tipo imaging e media player ; i tempi di esecuzione variano dai 3 ai 24 minuti circa. In un unico caso, CodeCarbonCopy ha fallito, a causa di particolari strutture di dati utilizzate dal software bmp2tiff .
In conclusione, CodeCarbonCopy rappresenta un buon punto di partenza per un futuro impiego intensivo del riutilizzo automatico del codice: i diversi vincoli presenti, al momento, impediscono notevolmente un suo potenziale utilizzo nel quotidiano . Difatti, oltre alla necessità di intervento umano, gli ostacoli principali sono due: la necessità che il codice sorgente e quello di destinazione prendano in input solamente un parametro – nello specifico un file – ed il funzionamento esclusivo con programmi scritti utilizzando il linguaggio di programmazione C.
Elia Tufarolo
Ti potrebbe interessare





3 ott 2017