
Roma – Terzo appuntamento dello speciale sulla tecnologia RFID . Nelle precedenti puntate ho illustrato, per sommi capi, l’evoluzione storica della tecnologia e il funzionamento fisico degli apparati, identificando le limitazioni a cui sono sottoposte le varie tipologie di transponder:
– Attivi: grandi distanze di lettura ma tempo di vita dipendente dalla batteria;
– Passivi magnetici: campo di lettura di massimo un metro;
– Passivi elettrici: campo di lettura inefficace a breve distanza e distanza massima per letture certe fino a 10 metri (la distanza massima è fortemente influenzata dalle normative sulle emissioni elettromagnetiche di ogni singolo stato).
Quest’oggi completerò la parte tecnica approfondendo la parte relativa alla comunicazione tag-reader e alle norme ISO, concetti che ci permettono di districarci nei meandri delle varie tipologie di prodotto.
Il processo di comunicazione sulla portante RF avviene attraverso l’elaborazione dei “disturbi” causati dai tag immersi nel campo elettromagnetico, mentre la velocità di comunicazione tag-reader è funzione della frequenza utilizzata (è un suo sottomultiplo, gli shunt vengono codificati secondo un determinato codice) ed è funzione dell’algoritmo anticollisione utilizzato per la lettura.
Come spiegato negli articoli precedenti, il processo di comunicazione fallisce nel caso che due tag cerchino di comunicare contemporaneamente (effetto collisione) in quanto la comunicazione ricevuta dal reader è la fusione di due comunicazioni, e come tale indecifrabile. Per ottimizzare l’uso della portante RF ed avere una certezza di lettura senza collisioni, si possono utilizzare due sistemi di codifica dell’anticollisione differenti: deterministico e stocastico. Entrambi i due approcci emettono una serie di impulsi (detti “bit-stop”) che determinano un ticchettio radio (come un metronomo, i cui spazi sono denominati “nibble” e dentro i quali vengono inviati i SID dei tag), questa serie è poi divisa in ulteriori segmenti chiamati “time-slot”. Un singolo time-slot permette ai tag di determinare quando trasmettere: in pratica il tag conta quanti battiti sono iniziati dall’inizio del time-slot, e se questo numero corrisponde al suo ultimo numero del SID il tag emette il suo SID. Questo metodo di comunicazione, nel caso di una serie di tag sequenziale (ideale), è ottimale perchè ogni tag sa quando emettere e non avvengono collisioni. Nel caso reale, dove esistono due o più tag con la cifra finale del SID identica, è necessario un sistema che permetta l’identificazione di entrambi i tag: l’algoritmo anticollisione.
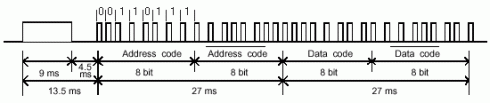
L’approccio deterministico all’algoritmo anticollisione ha una struttura lineare di ricerca dei SID dei tag: in pratica, ad ogni collisione, il reader chiede ai tag di contare i time-slot come se fossero la seconda cifra da destra del SID, così da ottenere gli ultimi 2 numeri del SID e permettere di dividersi il tempo di emissione senza collisioni (nel caso di seconda cifra identica, si passa alla terza e così via).
L’approccio stocastico sfrutta sempre il sistema della battitura, solo che in caso di collisione, continua la lettura dei successivi ed elabora i tag collisi in un secondo momento; all’atto dell’elaborazione della collisione, il reader interrogherà solo i tag collisi inviando un comando che identifica la parte del time-slot collisa (preavvisando quindi gli altri tag al silenzio) e la richiesta della seconda cifra da destra come un time-slot normale, ottenendo le due letture separate (il processo si ripete per tag con più di 2 cifre identiche). È facile comprendere che l’algoritmo di tipo B è più performante del tipo A. Nella normalizzazione delle infrastrutture, i tag tipo A saranno sempre deterministici, i tag tipo B saranno sempre stocastici (l’esempio degli algoritmi di tipo A e B sono presenti nell’ISO 14443-3). Entrambi gli algoritmi anticollisione contengono i comandi per eseguire la lettura/scrittura dei dati contenuti nei tag oltre il suo SID. Il processo di lettura/scrittura dei dati all’interno di un tag è univoco, cioè il reader impone il silenzio a tutti i tag eccetto quello per il quale vuole ottenere i dati ivi contenuti oppure scriverne di nuovi: questo presuppone naturalmente una previa lettura del SID da interrogare o aggiornare. Nei sistemi ISO (ed in particolare nel 15693) la memoria è organizzata per pagine, cioè aggregazioni di 8 byte: ogni 8 byte è presente un singolo bit di status (che può assumere valori di 0 od 1). Il bit di status è di fondamentale importanza quando i dati presenti nel tag devono essere preservati in quanto i dati sono scrivibili fintanto che lo status della pagina è posto a 0: quando quest’ultimo viene settato ad 1 i dati e lo stesso bit di status non possono mai più essere modificati, bloccando perennemente il dato contenuto.
Ricollegandomi alla recente notizia ” Come ti cracco l’RFID con un PDA ” pubblicata su queste stesse pagine, vorrei precisare che il cracking è stato possibile semplicemente a causa di una cattiva implementazione del sistema RFID da parte dei tecnici. Il sistema craccato funzionava così:
1) su ogni pacco viene apposta una etichetta RFID e nel suo interno vengono scritti i dati del codice a barre;
2) all’atto dell’acquisto i dati vengono semplicemente cancellati dal tag.
Si desume subito che il sistema è adatto per interfacciarsi con i vecchi codici a barre, ma per venire incontro alle problematiche di privacy, il tag viene cancellato all’uscita. Il cracker non ha modificato il SID né ha in alcun modo violato la tecnologia; anzi, ne ha sfruttato le sue potenzialità: con un palmare ed un reader portatile (ne esistono alcuni in formato CompactFlash con distanze di lettura nell’ordine dei 4 cm) ha eseguito una semplice lettura e cancellazione delle pagine di memoria (non bloccate perché da cancellare all’uscita), quindi il prodotto è risultato non più identificabile dal sistema informativo presente nel supermercato. Questo è accaduto perché è stato fatto un uso scorretto della tecnologia RFID oltre ad una scelta infelice della tipologia di tag da usare (esistono tag con algoritmi studiati specificatamente per le transazioni bancarie, quindi molto sicuri). Un sistema normale avrebbe associato, in un database interno al sistema informativo, il dato del SID con il dato del codice a barre per poi elaborarlo o cancellarlo, lasciando quindi inalterata la struttura del tag (ed utilizzandolo esclusivamente per l’identificazione ). Un sistema idoneo dovrebbe dovuto funzionare così:
1) su ogni pacco viene apposta un’etichetta RFID ed in un apposito database vengono scritti i dati del codice a barre associati al SID;
2) all’atto dell’acquisto viene letto il codice SID, convertito dal database nel relativo codice a barre ed elaborato per il pagamento.
Infine è bene chiarire che non è possibile modificare i dati del SID, in quanto questi vengono inseriti fisicamente dal produttore dei tag all’atto della produzione, così come non è possibile modificare i dati scritti se lo stato delle pagine è impostato ad 1. L’unica possibilità di violare la tecnologia è rompere il tag o guastare totalmente il chip (cancellando brutalmente con eccesso di calore o radiazioni X o UV tutto, compreso numero SID, algoritmo di collisione, sistema di comunicazione: dopo un simile trattamento il tag potrebbe non rispondere nemmeno più al reader). All’inizio della storia dei transponder di natura non aereonautica, la normalizzazione delle procedure di produzione (e di conseguenza di tutti gli apparati visti fino ad ora) erano alquanto flessibili: questa scelta fu presa per permettere un’evoluzione tecnologica quanto più svincolata da norme e regolamenti burocratici, permettendo quindi l’affermazione di uno o più standard sulla base delle effettive capacità o usi derivati. Successivamente si rese necessaria l’emissione di standard per permettere l’intercomunicazione, scambio ed interoperabilità tra apparecchiature e prodotti di diversi produttori. Allo stato attuale, le tipologie di tag passivi non sono state completamente normalizzate proprio per permetterne l’evoluzione non condizionata (la banda magnetica è stata studiata e normalizzata, la banda UHF è ancora libera anche se, come vedremo in seguito, va affermandosi ).
La differenziazione delle tipologie di tag normalizzati viene classificata attraverso determinate norme ISO che impongono ai vari produttori, nel caso decidano di sviluppare un prodotto non esclusivamente funzionante con la loro tecnologia, tutta una serie di prescrizioni generali atte alla produzione di infrastrutture formalmente uguali tra di loro, permettendone quindi l’interoperabilità: per fare un esempio, un tag della Texas Instruments, se rispetta l’ISO 15693, può essere letto da qualunque lettore che supporti tale standard. I due standard più utilizzati in campo magnetico sono il 14443 ed il 15693. Entrambe queste normative sono suddivise in sottocapitolati dove vengono definite delle regole su “Algoritmi di comunicazione RF”, “Algoritmi di comunicazione con altre apparecchiature” (RS232, RS494, ecc.), “Frequenze utilizzate”, “Boxatura e stampabilità”, “Struttura intrinseca”, “Filiera di produzione”, “Requisiti minimi”, “Potenze di emissione massime”, “Regole cogenti”. Queste norme ISO non sono “imposte”: qualunque produttore può decidere di applicare le norme parzialmente o di aggiungere alle norme parti esclusivamente propietarie (con rispetto, ovviamente, alle normative locali sulle emissioni elettromagnetiche ecc.). Un esempio è dato dall’algoritmo anticollisione, e in particolare dalla parte riguardante il campo RF dell’ ISO 15693, sia A che B: Texas Instruments ha aggiunto il suo protocollo TAG-IT, invece Philips il suo ICODE (i prodotti prendono i nomi dai protocolli), questo fa sì che un lettore che supporta lo standard 15693 legge entrambi i prodotti, un lettore che oltre questo standard supporta lo standard nativo del tag, legge con meno collisioni quel prodotto tag.
Vediamo gli elementi normalizzati e comuni alla maggior parte di lettori e tag:
– frequenze RF;
– comandi standard del lettore (reset CPU lettore, impostazioni porta RS, calibrazione campo RF);
– comandi standard lettura RF (tipo di lettura, lettura dei dati contenuti, comandi protocollo anticollisione);
– comandi standard scrittura RF (scrittura e bloccaggio perenne dati)
– risposte e messaggi d’errore.
A questi spesso vengono aggiunti:
– controllo apparecchiature esterne;
– protocolli proprietari;
– sistemi accessori nei tag (ad esempio, i tag ICODE hanno anche un sistema EAS).
Il sistema ISO è alquanto articolato, anche perchè spesso i riferimenti tecnici sono incrociati. La normativa generale che racchiude i parametri per l’identificazione e l’uso per lo scambio internazionale (quindi l’utilizzabilità per tutte le normative sulle emissioni elettromagnetiche internazionali) è l’ISO 7810. Qui vengono descritti i parametri per le ISO 10536 (“close-coupled card”), ISO 14443 (“proximity card”), ISO 15693 (“vicinity card”), ISO 10373
(“proximity and vicinity card”), ISO 9798-2 (procedura mutuale di
comunicazione TAG-Reader per la sicurezza in campo pagamenti – cifratura dei dati). Non è invece ancora presente una normativa per i tag UHF, in quanto troppo recenti: per questa categoria è
in fase di redazione la ISO 18000.
Sostanzialmente, a parte i livelli di emissione elettromagnetica (e relativi test) ed i protocolli RF e PC-Reader, le normative
lasciano ampio spazio alla creatività dei produttori.
Le frequenze in campo magnetico più utilizzate sono:
– 125/134 KHz, di norma utilizzate per transponder passivi a basso
costo, con consumi accettabili e ottima capacità di penetrazione in
materiali metallici, non metallici ed acqua. Spesso vengono utilizzati per il controllo animale o per badge di prossimità per il controllo accessi;
– 6,78 MHz, utilizzabile in ogni paese, di fattura ed uso
simile ai tag da 13,56 MHz;
– 13,56 MHz, utilizzabile in tutto il mondo, con una velocità di
trasmissione pari a 106 Kbit/s e un basso costo di produzione per i tag passivi, è lo standard attualmente più diffuso;
– 27,125 MHz, utilizzata per applicazioni ferroviarie speciali.
Le frequenze in campo UHF sono diverse da paese a paese, in italia per i tag attivi sono disponibili due frequenze (433 MHz, per il campo ferroviario e 915 MHz per le applicazioni commerciali come il Telepass); per i Tag Passivi si può utilizzare la frequenza ad 868 MHz, una delle poche che non richiede, per bassissime emissioni, una licenza di emissione.
È quindi possibile distinguere i tag sia per la frequenza utilizzata sia
per la normativa di riferimento a cui si appoggia il protocollo RF. Di fatto, in campo tecnico si identifica una famiglia di tag utilizzando uno schema simile a questo: tag passivo – 13,56 MHz – ISO 15693/B.
La rivoluzione più importante di questa tecnologie è stata la progettazione e la realizzazione di etichette flessibili, autoadesive e stampabili, oggi comunemente denominate tag RFID. La tecnologia utilizzata da queste etichette è a 13,56 MHz su protocollo ISO 15693 (A/B). Questa frequenza permette l’uso dell’etichetta in tutto il mondo e l’algoritmo RF e Reader-PC è semplice e di basso costo.
Nel prossimo articolo tratteremo come utilizzare correttamente i tag, quali sono le applicazioni reali in essere oggi, i limiti dei tag, i problemi di privacy, le evoluzioni con EPCGlobal e UHF.
Ti potrebbe interessare


8 ott 2004